ANNA: Automatic Neural Network Acceleration¶
Attention
Access to Qlip requires an API token from the TheStage AI Platform and additional access, which can be requested by contacting frameworks@thestage.ai.
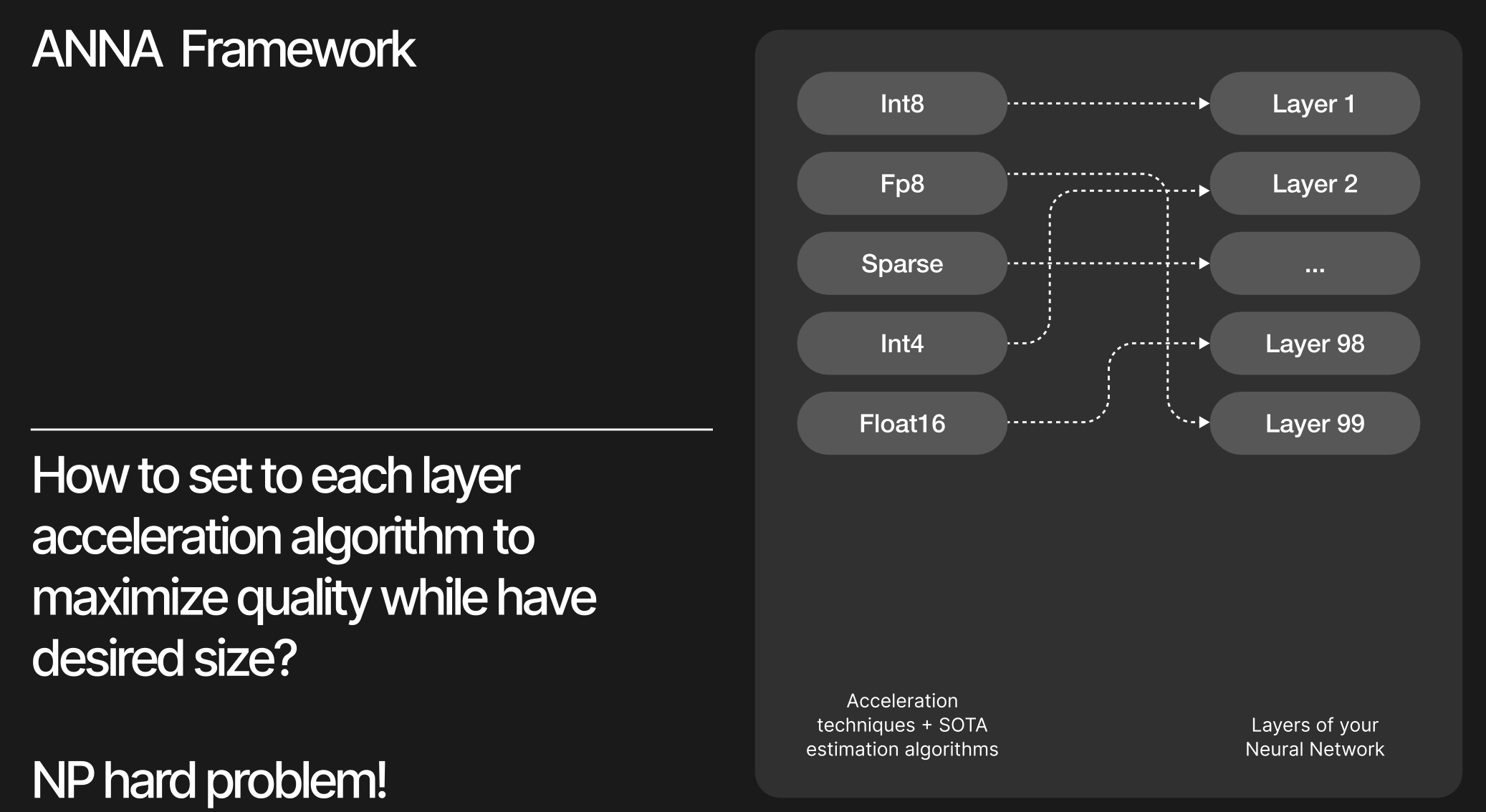
ANNA (Automatic Neural Network Analysis) is a framework designed to automatically identify optimal model compression configurations by exploring various algorithms and hyperparameters, while assessing the trade-offs between model size, performance, and accuracy.
Here we will cover the following topics:
Overview¶
Why Use ANNA?¶
Automatic model compression: ANNA automatically identifies optimal compression configurations for your model by exploring various algorithms and hyperparameters.
Controlable model size and performance constraints: ANNA allows you to set exact model size and performance constraints, such as MACs, model size, etc.
Configurable bag of algorithms: ANNA allows to configure a bag of algorithms to explore for any compression technique, such as quantization, pruning, etc. It will find the best mix of algorithms to satisfy your constraints and minimize the quality degradation of the model.
Flexible model and task support: ANNA can be configured for any model architecture, task, and deployment device.
Post-training compression: ANNA operates entirely in a post-training regime, requiring only calibration data for forward passes through the model. It doesn’t require any retraining or fine-tuning.
User-friendly: ANNA provides a user-friendly interface to configure the analysis and visualize the results.
Analysis Workflow¶
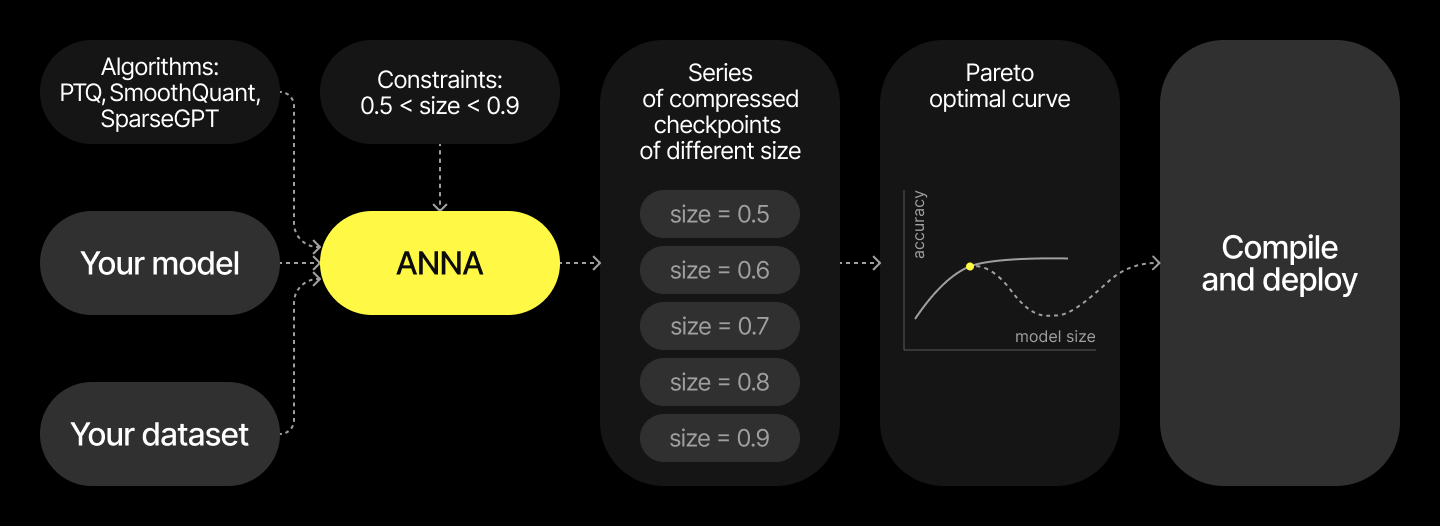
ANNA follows a systematic approach to model compression analysis through a well-defined workflow:
Import ANNA: Import the framework and necessary components for your use case.
Configure compression algorithms: Set up a bag of algorithms supported by your target device. This defines the algorithm space ANNA will explore during optimization.
Select model blocks: Identify specific modules within your model for analysis. ANNA will intelligently select the optimal algorithm from the bag for each block or leave it uncompressed to maximize quality while satisfying your constraints.
Initialize the Analyser: Create an Analyser with your model, algorithm bag, blocks, and calibration data. Configure task-specific parameters such as loss functions and data preparation.
Run analysis with constraints: Define performance constraints (size, MACs, memory) and execute analysis. ANNA finds Pareto-optimal configurations balancing quality against constraints.
Evaluate and visualize: Assess configurations by quality metrics and visualize trade-offs. Select configurations that meet deployment requirements.
Deploy optimal configuration: Apply the selected configuration to your model. The resulting
QlipConfigcan be used for hardware-specific compilation.
API Reference¶
Analyser API¶
- class qlip_algorithms.anna.Analyser¶
Core ANNA analyser that generates Pareto-optimal compression configurations across constraint values.
The Analyser orchestrates the entire ANNA workflow: it applies a bag of compression algorithms to create model variants, performs loss estimation, and executes optimization sweeps across constraint ranges to find optimal compression configurations. Each configuration represents a point on the Pareto frontier balancing model quality against performance metrics like size or computational cost.
Parameters
model: torch.nn.Module - PyTorch model to analyse and compress
bag_of_algorithms: BagOfAlgorithms - Collection of compression algorithms to evaluate and select from
block_names: List[str] - Names of specific modules within the model to analyse (e.g., transformer layers, conv blocks)
train_dataloader: DataLoader - Data for algorithm calibration and loss estimation during analysis
val_dataloader: Optional[DataLoader] = None - Separate validation data for real loss evaluation (uses train_dataloader if None)
dtype: torch.dtype = torch.float32 - Data type for tensors and computations
convex_loss: BaseConvexLoss = None - Convex loss function to optimize for. If None, then
taskargument value is used.task: str = ‘classification’ - Task type for automatic loss function selection (‘classification’ or ‘regression’). When ‘classification’ is specified,
convex_lossdefaults toCrossEntropyLoss; when ‘regression’ is specified,convex_lossdefaults toMSELoss.calibration_iterations: int = 1024 - Number of batches for algorithm calibration and statistics collection
ddp: bool = False - Whether to enable Distributed Data Parallel processing for multi-GPU analysis
Public Methods¶
- Analyser.run(min_constraint_value=0.5, max_constraint_value=1.0, num_configs=1, constraint_values=None, constraint_type='size', loss_estimator='value', loss_estimator_kwargs=None, num_real_loss_batches=32) Dict[float, ANNAResult]¶
Performs comprehensive analysis sweep across constraint values to find optimal compression configurations.
This method is the primary interface for ANNA analysis. It creates a series of optimization problems with different constraint values, solves each to find the optimal algorithm combination.
Parameters
min_constraint_value: float = 0.5 - Minimum constraint value for the sweep (e.g., 0.5 = 50% of original size)
max_constraint_value: float = 1.0 - Maximum constraint value for the sweep (e.g., 1.0 = 100% of original size)
num_configs: int = 1 - Number of configurations to generate evenly spaced between min and max
constraint_values: Optional[List[float]] = None - Specific constraint values to use instead of linear spacing
constraint_type: str = ‘size’ - Type of constraint to optimize (‘size’ for model size, ‘macs’ for computational cost)
loss_estimator: Union[str, BaseLossEstimator] = ‘value’ - Loss estimation method (‘value’ for fast approximation, ‘grad’ for gradient-based, or custom estimator)
loss_estimator_kwargs: Optional[Dict[str, Any]] = None - Additional keyword arguments forwarded to the loss estimator (e.g., synchronization flags for DDP)
num_real_loss_batches: int = 32 - Number of validation batches for real loss evaluation (0 to skip real loss evaluation)
Returns
Dict[float, ANNAResult]: Dictionary of constraint values to ANNAResult objects containing optimization results, QlipConfig for each constraint value, and optional real loss measurements.
- class qlip_algorithms.anna.LLMAnalyser¶
Specialized ANNA analyser optimized for Large Language Models with automatic HuggingFace integration.
LLMAnalyser extends the base Analyser with LLM-specific functionality including automatic model loading from HuggingFace Hub, dataset preparation with proper tokenization, and handling of transformer-specific data formats. It automatically identifies Linear layers for analysis and handles the complexities of language model data preprocessing.
Parameters
model_name: str - HuggingFace model identifier (e.g., ‘gpt2’, ‘meta-llama/Meta-Llama-3.1-8B’)
bag_of_algorithms: BagOfAlgorithms - Collection of compression algorithms to evaluate
block_names: Optional[List[str]] = None - Specific layer names to analyse (auto-detects Linear layers if None)
dataset_name: str = ‘wikitext/wikitext-2-raw-v1’ - HuggingFace dataset name with optional config
train_dataloader: Optional[DataLoader] = None - Pre-built training dataloader (creates automatically if None)
val_dataloader: Optional[DataLoader] = None - Pre-built validation dataloader (uses train_dataloader if None)
tokenizer: Optional[AutoTokenizer] = None - Pre-loaded tokenizer (loads automatically if None)
dtype: torch.dtype = torch.float16 - Data type optimized for LLM memory efficiency
calibration_iterations: int = 1024 - Number of batches for calibration
batch_size: int = 8 - Batch size for data loading and processing
max_length: int = 1024 - Maximum sequence length for tokenization
hf_token: Optional[str] = None - HuggingFace authentication token for private models
use_elastic_models: bool = False - Whether to use elastic_models library for model loading
cache_dir: Optional[str] = None - Directory for caching downloaded models and datasets
ddp: bool = False - Whether to use Distributed Data Parallel for multi-GPU processing
- class qlip_algorithms.anna.PipelineAnalyser¶
Specialized ANNA analyser for diffusion pipelines and complex multi-component models.
PipelineAnalyser is designed for analyzing individual components within larger pipelines, particularly useful for diffusion models like Stable Diffusion where the UNet or transformer component needs compression analysis. It handles activation saving and loading for models where collecting calibration data requires running complex generation pipelines.
Parameters
pipeline: Pipeline - The diffusion or generation pipeline containing the component to analyse
bag_of_algorithms: BagOfAlgorithms - Collection of compression algorithms to evaluate
block_names: List[str] - Names of specific modules within the component to analyse
component_name: str = ‘transformer’ - Name/path of component within pipeline (e.g., ‘unet’, ‘transformer’, ‘text_encoder’)
activations_dataset_path: str = ‘./activations’ - Directory path for saving and loading activation data
calibration_iterations: int = 1024 - Number of batches for calibration
batch_size: int = 1 - Batch size for activation processing
dtype: Optional[torch.dtype] = None - Data type (uses pipeline’s dtype if None)
ddp: bool = False - Whether to use Distributed Data Parallel
Abstract Methods
run_pipeline_to_save_activations() - Must be implemented by subclasses to define how the pipeline should be executed to generate calibration activations. This method should contain the specific pipeline calls needed to exercise the target component.
Bag of Algorithms¶
- class qlip_algorithms.anna.BagOfAlgorithms¶
Abstract base class for collections of compression algorithms used in ANNA analysis.
The BagOfAlgorithms pattern enables systematic exploration of compression algorithm combinations by encapsulating multiple algorithm variants with different hyperparameters into a single collection. Each bag creates memory-efficient model variants that share the original model’s parameters while applying different compression strategies, allowing ANNA to efficiently compare their trade-offs.
This design pattern provides:
Algorithm Abstraction: Uniform interface for different compression techniques (quantization, pruning, distillation)
Hyperparameter Exploration: Automatic generation of algorithm variants with different configurations
Memory Efficiency: Model variants share underlying parameters, reducing memory overhead during analysis
Extensibility: Easy addition of new compression algorithms through subclassing
Distributed Support: Built-in support for distributed training and calibration
Note
This is an abstract base class. Use concrete implementations like
PTQBagorSmoothQuantBag, or create custom bags by subclassing and implementingget_algorithms().Abstract Methods¶
- BagOfAlgorithms.get_algorithms(ddp=False) List[Tuple[type, Dict[str, Any]]]¶
Abstract method that must be implemented by subclasses to define which algorithms and configurations to include.
Parameters
ddp: bool = False - Whether distributed data parallel is being used, affects algorithm configuration
Returns
List[Tuple[type, Dict]]: List of (algorithm_class, parameters_dict) tuples for each variant
Example Implementation
def get_algorithms(self, ddp=False): return [ (PostTrainingQuantization, {'weights_scheme': {'n_bit': 8}}), (PostTrainingQuantization, {'weights_scheme': {'n_bit': 4}}), ]
Public Methods¶
- BagOfAlgorithms.apply(model, modules_names, calibration_dataloader, unpack_batch=None, ddp=False) List[torch.nn.Module]¶
Creates compressed model variants by applying all algorithms from the bag to model copies. Each variant is calibrated using the provided dataloader and shares parameters with the original model for memory efficiency.
Note
Primary method used by
Analyserclass during ANNA analysis.Parameters
model: torch.nn.Module - Original PyTorch model to compress
modules_names: List[str] - Fully-qualified module names to which each algorithm will be applied (blocks under analysis)
calibration_dataloader: DataLoader - Data for algorithm calibration and statistics collection
unpack_batch: Optional[Callable] = None - Function to extract (args, kwargs) from batch for model.forward()
ddp: bool = False - Whether to enable Distributed Data Parallel processing
Returns
List[torch.nn.Module]: List of compressed model variants, one for each algorithm configuration
- BagOfAlgorithms.need_calibration(algorithm, alg_kwargs) bool¶
Determines whether a specific algorithm requires calibration. Can be overridden by subclasses to implement algorithm-specific calibration logic.
Parameters
algorithm: type - Algorithm class to check
alg_kwargs: Dict[str, Any] - Algorithm-specific parameters
Returns
bool: True if calibration is needed (default), False otherwise. For example, dynamic quantization modes may not require calibration.
- BagOfAlgorithms.calibrate(model, managers, dataloader, algorithm, alg_kwargs, unpack_batch=None)¶
Runs calibration process for a specific algorithm on a model. Configures the model for calibration mode and processes batches to collect necessary statistics.
Parameters
model: torch.nn.Module - Model with algorithm applied
managers: Dict[str, Any] - Dictionary of algorithm managers (quantization, adapter, etc.)
dataloader: DataLoader - Calibration data
algorithm: type - Algorithm class being calibrated
alg_kwargs: Dict[str, Any] - Algorithm-specific parameters
unpack_batch: Optional[Callable] = None - Batch unpacking function
- class qlip_algorithms.anna.PTQBag¶
Bag of
PostTrainingQuantizationalgorithms with different hyperparameters. When applied, it creates multiple model variants by combining different quantization configurations with various observer percentile settings. For each quantization configuration with quantized activations (n_bit < 32), it generatesnum_different_scalesvariants using percentile values linearly distributed betweenpercentile_range. For configurations with full-precision activations (n_bit >= 32), it creates a single variant. The different percentiles control how the observers estimate quantization scale parameters during calibration, affecting the trade-off between clipping outliers and preserving dynamic range.Parameters
quantization_configs: List[Dict] - List of quantization configuration dictionaries, each containing scheme parameters like bit-width, data type, and granularity for weights and activations.
calibration_iterations: int = 1024 - Maximum number of calibration batches to process for collecting activation statistics during quantization setup.
percentile_values: List[float] = [0.0] - Explicit list of percentile values used by observers to estimate activation ranges (values represent left-tail clipping; right-tail is 1 - value). For each config with quantized activations (n_bit < 32), a variant is created per percentile.
weights_scale_offset_dtype: Optional[torch.dtype] = torch.float32 - Data type for storing quantization scale and zero-point parameters for weights. Higher precision (float32) provides more accurate quantization but uses more memory.
activations_scale_offset_dtype: Optional[torch.dtype] = torch.float32 - Data type for storing quantization scale and zero-point parameters for activations.
attention_cls: str = None - Name of attention module class (e.g., ‘MultiheadAttention’). When specified, enables placement=’attention’ setup for such modules in addition to input placement.
- class qlip_algorithms.anna.SmoothQuantBag¶
Bag of
SmoothQuantalgorithms with different alpha hyperparameters for transformer model quantization. SmoothQuant addresses activation outliers in transformer models by mathematically migrating quantization difficulty from activations to weights through channel-wise scaling. For each quantization configuration, it creates multiple variants with different alpha values that control the smoothness transfer ratio. Higher alpha values (closer to 1.0) transfer more quantization difficulty to weights, while lower values preserve more activation dynamics. The algorithm uses a two-phase calibration: first collecting activation statistics for equalization, then calibrating quantizers with the smoothed distributions.Parameters
quantization_configs: List[Dict] - List of quantization configuration dictionaries, each containing scheme parameters for weights and activations quantization.
transformer_block_type: str - Name of transformer block class (e.g., ‘TransformerBlock’, ‘LlamaDecoderLayer’) used to identify transformer blocks in the model for applying channel-wise smoothing.
calibration_iterations: int = 1024 - Number of calibration batches for each phase: activation statistics collection and quantizer calibration.
alpha_values: List[float] = [0.8] - List of smoothness migration factors. Each alpha creates a model variant with different outlier handling. Alpha=0.5 balances difficulty equally, alpha=0.8 shifts more difficulty to weights, alpha=1.0 maximally smooths activations.
weights_scale_offset_dtype: Optional[torch.dtype] = torch.float32 - Data type for storing quantization scale and zero-point parameters for weights.
activations_scale_offset_dtype: Optional[torch.dtype] = torch.float32 - Data type for storing quantization scale and zero-point parameters for activations.
- class qlip_algorithms.anna.CompositeBag¶
Composite bag that combines multiple BagOfAlgorithms instances into a unified collection.
CompositeBag implements the Composite pattern to create hierarchical algorithm collections by aggregating multiple bag instances. When applied to a model, it sequentially applies each constituent bag, collecting all their algorithm variants into a single comprehensive set. This enables complex algorithm exploration strategies that combine different compression approaches (e.g., quantization + pruning, or multiple quantization strategies with different hyperparameters).
Key Features:
Algorithm Aggregation: Combines variants from multiple specialized bags into one collection
Heterogeneous Mixing: Enables mixing different compression techniques (quantization, pruning, distillation)
Modular Composition: Build complex strategies from simpler, reusable bag components
Transparent Interface: Behaves like any other BagOfAlgorithms for seamless integration
Memory Efficiency: Maintains the shared parameter optimization of constituent bags
Parameters
bags: List[BagOfAlgorithms] - List of bag instances to combine. Each bag contributes its algorithm variants to the composite collection.
Example Usage
from qlip_algorithms.anna import PTQBag, SmoothQuantBag, CompositeBag # Create individual algorithm bags ptq_bag = PTQBag( quantization_configs=[NVIDIA_FP8_W8A8], calibration_iterations=1024, ) smooth_bag = SmoothQuantBag( quantization_configs=[NVIDIA_FP8_W8A8], alpha_values=[0.5, 0.8, 1.0], calibration_iterations=1024, ) # Combine bags for comprehensive exploration composite_bag = CompositeBag([ptq_bag, smooth_bag])
Concrete Implementation Example
The
W8A8StaticBagclass demonstrates CompositeBag usage by combining PTQ and SmoothQuant approaches:class W8A8StaticBag(CompositeBag): def __init__(self, type='int', calibration_iterations=1024): # Create PTQ bag with explicit percentile variations ptq_bag = PTQBag( quantization_configs=configs, percentile_values=[0.0, 0.02, 0.05, 0.1, 0.15], calibration_iterations=calibration_iterations, ) # Create SmoothQuant bag with alpha variations smooth_bag = SmoothQuantBag( quantization_configs=configs, alpha_values=[0.2, 0.4, 0.6, 0.8, 1.0], calibration_iterations=calibration_iterations, ) # Combine both approaches super().__init__([ptq_bag, smooth_bag])
Loss Functions¶
ANNA uses a sophisticated loss estimation framework to predict model quality degradation during compression analysis. This framework consists of convex loss functions for different tasks and loss estimators that create quadratic approximations of the loss landscape.
Convex Loss Functions
Convex loss functions define the optimization objective for ANNA analysis. These functions must be convex to ensure reliable optimization and meaningful quality estimation. ANNA provides built-in loss functions for common tasks and supports custom loss functions for specialized applications.
- class qlip.analysis.loss.BaseConvexLoss¶
Abstract base class for all convex loss functions used in ANNA analysis.
BaseConvexLoss defines the interface for loss functions that measure the quality degradation between compressed and original model outputs. All loss functions must be convex to ensure the optimization problem remains tractable and produces meaningful results during algorithm selection.
Key Requirements:
Convexity: Loss function must be convex with respect to the prediction differences
Differentiability: Must support gradient computation for optimization
Batch Processing: Must handle batched inputs efficiently
Deterministic: Should produce consistent results for the same inputs
Abstract Methods
forward(predicts, targets) -> torch.Tensor - Computes loss between model predictions and target outputs
predicts: torch.Tensor - Outputs from the compressed model variant
targets: torch.Tensor - Reference outputs from the original model (detached)
Returns: torch.Tensor - Scalar loss value measuring quality degradation
Usage Example
from qlip.analysis.loss import BaseConvexLoss import torch.nn.functional as F class CustomCosineLoss(BaseConvexLoss): def forward(self, predicts, targets): # Ensure targets are detached to prevent gradient flow similarity = F.cosine_similarity(predicts, targets.detach(), dim=-1) return 1 - similarity.mean() # Convert similarity to distance
- class qlip.analysis.loss.MSEConvexLoss¶
Mean Squared Error loss function for regression tasks and continuous output models.
MSEConvexLoss computes the element-wise squared differences between compressed model predictions and original model outputs. This loss is particularly suitable for regression tasks, generative models, and scenarios where the model outputs are continuous values. The function ensures targets are detached to prevent gradient backpropagation through the reference model.
Mathematical Formulation
\[L_{MSE}(y_{pred}, y_{target}) = \frac{1}{N} \sum_{i=1}^{N} (y_{pred,i} - y_{target,i})^2\]where \(N\) is the total number of elements across the batch.
- class qlip.analysis.loss.KLDivergenceConvexLoss¶
Kullback-Leibler divergence loss for classification tasks and probability distribution matching.
KLDivergenceConvexLoss measures the difference between probability distributions produced by compressed and original models. This loss is ideal for classification tasks where maintaining the output probability distribution is crucial. The temperature parameter allows for smoothing of the probability distributions, which can improve optimization stability.
Parameters
temperature: float = 1.0 - Temperature scaling factor for softmax distributions. Higher values create smoother distributions, lower values create sharper distributions.
Mathematical Formulation
\[L_{KL}(y_{pred}, y_{target}) = \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{C} p_{target,i,j} \log\frac{p_{target,i,j}}{p_{pred,i,j}}\]where \(p_{pred} = \text{softmax}(y_{pred}/T)\) and \(p_{target} = \text{softmax}(y_{target}/T)\), \(T\) is temperature, \(N\) is batch size, and \(C\) is number of classes.
Results and Artifact Management¶
- class qlip_algorithms.anna.ANNAResult¶
Container class for ANNA analysis results.
This class stores the results of an ANNA analysis run, including the optimal configuration, objective values, and any generated artifacts (images, videos, etc.). It provides methods for saving and loading results with all associated metadata.
Attributes
constraint_value: float - The constraint value used for this result
objective_value: float - The optimization objective value achieved
anna_config: QlipConfig - The QlipConfig containing the optimal compression configuration for given constraint value
real_loss_value: float - The real loss value (if evaluated)
Public Methods¶
- ANNAResult.register_benchmarks(benchmarks) None¶
Register benchmark results for this configuration.
Parameters
benchmarks: Dict[str, Any] - Dictionary containing benchmark results
- ANNAResult.register_image(image, description=None) None¶
Register an image artifact.
Parameters
image: Any - Image object (PIL Image, numpy array, or PyTorch tensor)
description: Optional[str] = None - Optional description of the image
- ANNAResult.register_video(video, fps, description=None) None¶
Register a video artifact.
Parameters
video: Any - Video data (list of frames or video tensor)
fps: int - Frames per second for the video
description: Optional[str] = None - Optional description of the video
- ANNAResult.register_text(text, description=None) None¶
Register a text artifact.
Parameters
text: str - Text content to save
description: Optional[str] = None - Optional description of the text
- ANNAResult.register_audio(audio, sample_rate, description=None) None¶
Register an audio artifact.
Parameters
audio: Any - Audio data (numpy array or PyTorch tensor)
sample_rate: int - Sample rate of the audio
description: Optional[str] = None - Optional description of the audio
- ANNAResult.save(save_dir, save_meta_info=True) None¶
Save the ANNAResult and all its artifacts to disk.
This method creates a structured directory layout containing configuration files, metadata, benchmarks, and all registered artifacts organized by type.
Parameters
save_dir: str - Directory to save the result in
save_meta_info: bool = True - Whether to save metadata information
Basic ANNA example¶
Compress model to fit given size constraint¶
This example demonstrates how to use ANNA to obtain a quantized checkpoint suitable for NVIDIA hardware for ResNet20 with the given restriction that model size should be less than 60% of original size. We will:
Use
PTQBagwithNVIDIA_INT_W8A8quantization schemeImplement
ResnetAnalyserchild class ofAnalyserwithunpack_batchfor data preprocessingSet
task='classification'to useKLDivergenceConvexLossfor preserving classification distributionsUse CIFAR-10 dataset for calibration
import torch
import torchvision
from pytorchcv.model_provider import get_model
from qlip_algorithms.anna import Analyser, PTQBag
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
class ResnetAnalyser(Analyser):
def unpack_batch(self, batch):
# The function must return a tuple of model args and model kwargs dict
x = batch[0].to(self.device, dtype=self.dtype)
return (x,), {}
model = get_model("resnet20_cifar10", pretrained=True)
bag = PTQBag(quantization_configs=[NVIDIA_INT_W8A8], calibration_iterations=512)
# Prepare calibration data
cifar_dataset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True,
transform=torchvision.transforms.ToTensor()
)
calibration_dataloader = torch.utils.data.DataLoader(
dataset=cifar_dataset,
batch_size=8
)
# Run analysis
analyser = ResnetAnalyser(
model=model,
bag_of_algorithms=bag,
train_dataloader=calibration_dataloader,
task='classification',
)
results = analyser.run(
constraint_values=[0.6], # 0.6 means 60% of original model size
constraint_type='size' # constraint on model size
)
The output of the analysis is a dictionary of constraint values to ANNAResult objects containing a compression configuration and some additional information.
Apply the config to the model and evaluate the accuracy:
results[0.6].anna_config.apply(model) # Apply the compression configuration to the model
accuracy = evaluate_accuracy(model, cifar_dataset)
print(f'constraint value: {result.constraint_value}, accuracy: {accuracy}')
Explore trade-off between model compression and quality¶
Now let’s suppose that we do not have an exact restriction on model size and want to generate
a series of 10 checkpoints with different sizes to explore the trade-off between model compression and quality.
To do this set num_configs=10 and set the range of sizes starting from min_constraint_value=0.5 and ending with max_constraint_value=1.0.
results = analyser.run(
min_constraint_value=0.5,
max_constraint_value=1.0,
num_configs=10,
constraint_type='size'
)
Below we will loop over the results, apply the compression configuration to the model and evaluate the accuracy.
for constraint_value, result in results.items():
# Apply the compression configuration to the model
result.anna_config.apply(model)
accuracy = evaluate_accuracy(model, cifar_dataset)
print(f'constraint value: {constraint_value}, accuracy: {accuracy}')
# Clear the model from quantizers
result.anna_config.remove()
Configure a bag of algorithms¶
A bag of algorithms defines a set of compression algorithms and their hyperparameters ANNA will select among. Theoretically, more different choices will allow the analyser to find more flexible compression configurations leading to higher quality of the compressed model, but it comes with a cost of longer analysis time and more data samples required for calibration.
Listing hyperparameters of the algorithm in the bag¶
The previous example used a simple bag with one PTQ algorithm option.
Actually, in that example for each block of the model ANNA decides whether to quantize it or not.
Sometimes activation outliers cause poor accuracy with naive min-max range estimation,
in this case we can configure PTQBag with different percentile values for outlier removal.
ANNA will select the optimal percentile value for each module or leave it unquantized.
Provide explicit observer percentile values via percentile_values to explore different outlier clipping strategies. For example, this configuration uses values 0.01, 0.03, 0.05:
from qlip_algorithms.anna import PTQBag
bag = PTQBag(
quantization_configs=[NVIDIA_INT_W8A8],
percentile_values=[0.01, 0.03, 0.05],
calibration_iterations=512,
)
Mixing different bit widths¶
Let’s say we want to compress the model to 30% of the original size.
In this case 8-bit quantization may not be enough to achieve the desired compression rate, because the minimal feasible size would be 50% of the original size.
Below we show how to mix different bit widths like int8 weights with int4 weights in PTQBag.
from qlip_algorithms.anna import PTQBag
int4_weight_only = { # Define int4 weight quantization scheme
'weights_scheme': {'type': 'int', 'n_bit': 4, 'symmetric': True},
}
int8_weight_only = { # Define int8 weight quantization scheme
'weights_scheme': {'type': 'int', 'n_bit': 8, 'symmetric': True}
}
bag = PTQBag(
quantization_configs=[int4_weight_only, int8_weight_only],
calibration_iterations=512
)
...
# This will generate a configuration with 30% of original model size
analyser.run(
min_constraint_value=0.3, # 30% of original model size
num_configs=1,
constraint_type='size'
)
Using SmoothQuant algorithm¶
Sometimes PTQBag is insufficient to preserve model quality during compression. For instance, activations in Large Language Models
often contain outliers that make naive percentile-based quantization scale estimation work poorly.
In this case we can use a bag of SmoothQuant algorithms.
from qlip_algorithms.anna import SmoothQuantBag
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
bag = SmoothQuantBag(quantization_configs=[NVIDIA_INT_W8A8])
For even better quality use the dynamic quantization scheme NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
from qlip.compiler.nvidia import NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
bag = SmoothQuantBag(quantization_configs=[NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC])
SmoothQuant algorithm has a hyperparameter alpha that controls equalization strength (see Quantization Algorithms for more details).
In the following example we will list different values of alpha to give ANNA more options to find the optimal configuration.
bag = SmoothQuantBag(
quantization_configs=[NVIDIA_INT_W8A8],
alpha_values=[0.5, 0.8, 1.],
)
Mixing different algorithms¶
To avoid manually choosing between PTQ or SmoothQuant algorithms, we can provide both and ANNA will automatically select the optimal algorithm for each module in the model minimizing quality degradation.
from qlip_algorithms.anna import CompositeBag, PTQBag, SmoothQuantBag
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
# Create individual algorithm bags
ptq_bag = PTQBag(quantization_configs=[NVIDIA_INT_W8A8])
smooth_bag = SmoothQuantBag(quantization_configs=[NVIDIA_INT_W8A8])
# Combine both approaches using CompositeBag
bag = CompositeBag([ptq_bag, smooth_bag])
Select model blocks to be analysed¶
ANNA allows you to specify which blocks of the model will be used for compression analysis.
By default, Analyser will use all linear and convolutional layers in the model.
For each block ANNA will select one of the algorithms from the bag or keep the module unchanged.
In some cases you might want to specify a custom set of modules to be analysed. Here is an example of how to use all linears in the model except the last one:
modules_names = [
name for name, module in model.named_modules()
if isinstance(module, nn.Linear) and name != 'fc' # fc is the last linear layer
]
analyser = Analyser(
model=model,
bag_of_algorithms=bag,
block_names=modules_names, # list of module names to be analysed
train_dataloader=calibration_dataloader,
)
Note
Make sure that modules in the list are not repeated and are not submodules of another module in the list.
As another example, quantize attention modules with placement=’attention’ (see Quantization API) to use NVIDIA FP8 attention kernels.
In this case we should use entire attention modules as blocks for analysis instead of linear layers.
Pass the attention_cls argument to the bag of algorithms, instances of that class will be quantized with placement=’attention’.
from qlip.compiler.nvidia import NVIDIA_FLOAT_W8A8
from qlip_algorithms.anna import PTQBag
modules = [
name for name, module in model.named_modules()
if isinstance(module, Attention)
]
bag = PTQBag(
quantization_configs=[NVIDIA_FLOAT_W8A8],
attention_cls='Attention',
calibration_iterations=512
)
analyser = Analyser(
model=model,
bag_of_algorithms=bag,
block_names=modules,
train_dataloader=calibration_dataloader,
)
Customizing input and output data preprocessing¶
The Analyser class provides an unpack_batch method that can be overridden to handle custom data formats and preprocessing.
This method is called for each batch during calibration and determines how the input data is extracted and prepared for the model.
It should return a tuple of model args and model kwargs dict.
from qlip_algorithms.anna import Analyser
class CustomAnalyser(Analyser):
def unpack_batch(self, batch):
if isinstance(batch, dict):
inputs = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
return (), {'input_ids': inputs, 'attention_mask': attention_mask}
If model output is not a torch.Tensor then you need to override unpack_outputs_for_loss to extract the output tensor for loss calculation.
class CustomAnalyser(Analyser):
def unpack_outputs_for_loss(self, outputs):
return outputs.logits
Constraints types¶
ANNA allows you to specify different types of constraints.
To limit memory used by the model, use constraint_type='size'.
To limit computational complexity, use constraint_type='macs'.
results = analyser.run(
min_constraint_value=0.3,
max_constraint_value=1.0,
constraint_type='macs'
)
Note
MACs is a proxy metric for performance and sometimes it may not be exactly proportional to the inference time.
Custom loss functions¶
ANNA uses loss functions to quantify the quality degradation between original and compressed model outputs during optimization. The framework provides built-in loss functions for common tasks:
For classification tasks (
task='classification'), ANNA usesKLDivergenceConvexLossto measure distribution differences between original and compressed model predictionsFor regression tasks (
task='regression'), ANNA usesMSEConvexLossto measure mean squared error between outputs
Cosine distance loss example¶
Let’s assume we are working with an embedding model or tasks requiring specialized loss functions different from MSE and KL divergence.
For this ANNA provides the BaseConvexLoss class which can be used to define custom loss functions.
Below is an example of how to use cosine distance as a loss function.
from qlip.analysis import BaseConvexLoss
import torch
class CosineDistanceLoss(BaseConvexLoss):
def forward(self, predicts, targets: torch.Tensor):
return 1 - torch.nn.functional.cosine_similarity(predicts, targets.detach(), dim=-1).mean()
cosine_distance_loss = CosineDistanceLoss()
analyser = Analyser(
model=model,
bag_of_algorithms=bag,
block_names=modules,
train_dataloader=calibration_dataloader,
# pass the custom loss function to the analyser instead of setting task argument
convex_loss=cosine_distance_loss
)
Running with distributed data parallel¶
To run analysis with distributed data parallel, initialize the analyser with ddp=True and run the script with torchrun.
analyser = Analyser(
model=model,
bag_of_algorithms=bag,
train_dataloader=calibration_dataloader,
task='classification',
calibration_iterations=1024,
ddp=True
)
...
torchrun --nproc_per_node=4 anna_script.py
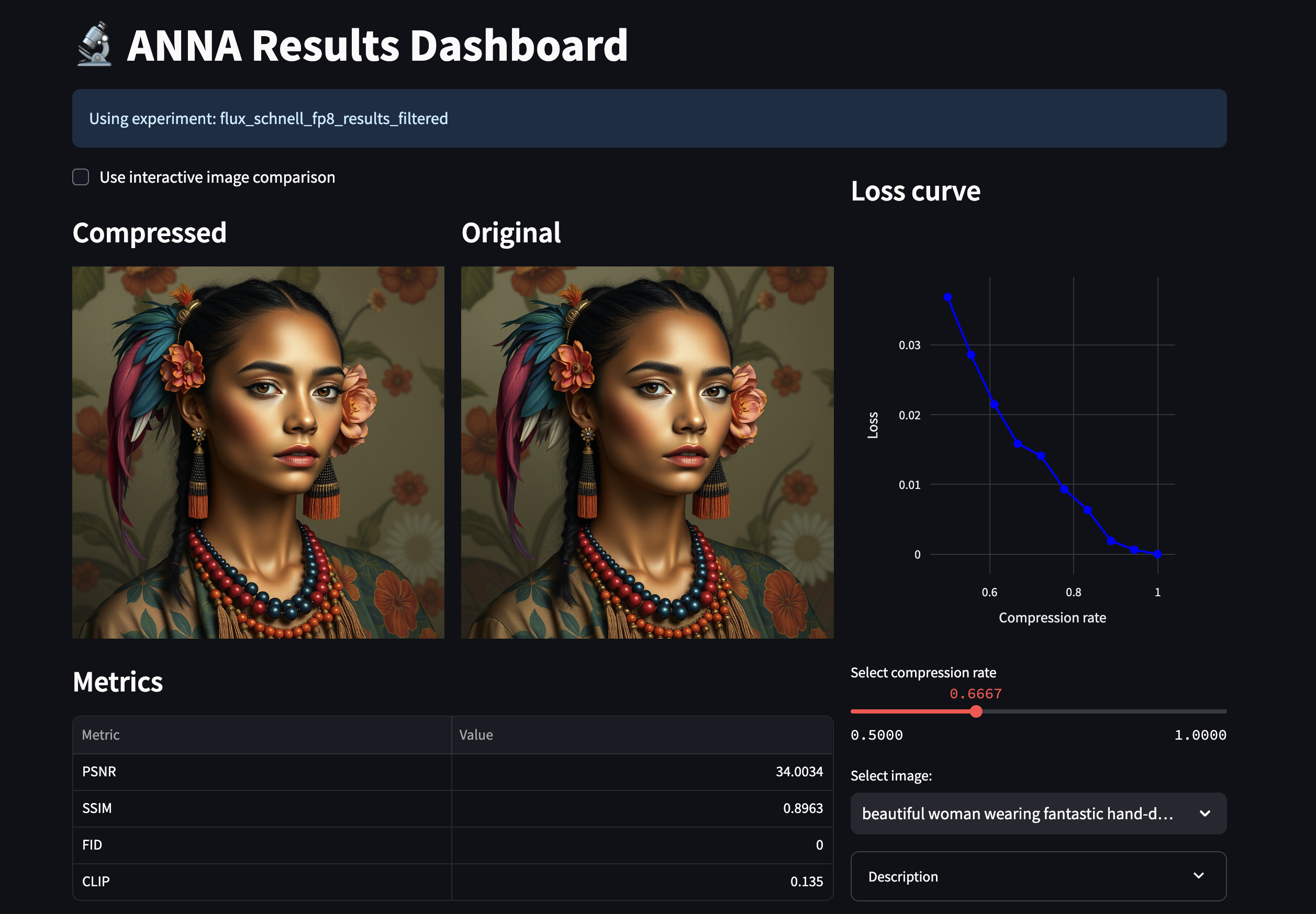
Evaluate and visualize results¶
The following example generates 10 compressed models with varying sizes, creates images for each configuration, and saves them for visualization.
results = analyser.run(
min_constraint_value=0.5,
max_constraint_value=1.0,
num_configs=10,
constraint_type='size'
)
for constraint_value, result in results.items():
# Apply the quantization configuration to the model
result.anna_config.apply(model)
# Generate images for each prompt and register them in the result object
for prompt in prompts:
image = pipeline(prompt)
result.register_image(image, description=prompt)
metrics = evaluate_metrics(model)
result.register_benchmarks(metrics)
# Clear the model from quantizers
result.anna_config.remove()
result.save('./anna_results')
Launch the interactive dashboard to visualize results. On the dashboard you can move the slider to compare different constraint values and see generated artifacts.
python -m qlip_algorithms.anna.dashboard --experiments-dir ./anna_results
Model serialization and deserialization¶
All information about compression configuration such as quantized modules, quantization scheme and state dicts are stored in the QlipConfig object.
To load the configuration from the disk and apply it to the model use the QlipConfig.load method.
from qlip import QlipConfig
config = QlipConfig.load('./anna_results/configs/config_0.5.pth')
config.apply(model)
Read the compression configuration from the model and save it to the disk:
config = QlipConfig.from_model(model)
config.save('./anna_results/configs/config_0.5.pth')
LLMs Analysis¶
Run analysis for Large Language Models (LLMs) using the LLMAnalyser class.
This specialized analyser is a subclass of the core Analyser class that simplifies the analysis workflow for transformer-based language models by automating model loading, tokenization, and calibration data preparation.
The LLMAnalyser provides several key advantages for LLM compression:
Automatic Model Loading: Directly loads models from Hugging Face Hub by model name, handling tokenizer setup and model initialization
Built-in Calibration Data: Automatically downloads and preprocesses text datasets from Hugging Face for calibration, eliminating the need for manual data preparation
Configured for Text Generation: Configured with appropriate
KLDivergenceConvexLossloss function to preserve the probability distributions of the predicted tokensBlock Detection: Automatically identifies transformer layers and attention blocks within the model architecture for targeted compression
from qlip_algorithms.anna import LLMAnalyser, W8A8StaticBag
# Create algorithm bags
bag = W8A8StaticBag(type='int', calibration_iterations=512)
# Initialize LLM analyser
analyser = LLMAnalyser(
model_name='meta-llama/Meta-Llama-3.1-8B',
bag_of_algorithms=bag,
dataset_name='wikitext/wikitext-2-raw-v1',
dtype=torch.bfloat16,
calibration_iterations=1024,
batch_size=8,
max_length=1024
)
# Run analysis across size constraints
results = analyser.run(
min_constraint_value=0.5, # 50% of original size
max_constraint_value=1.0, # 100% of original size
num_configs=10, # Generate 10 configurations
constraint_type='size', # Constraint on model size
)
for constraint_value, result in results.items():
result.anna_config.apply(model)
mmlu = evaluate_mmlu(model)
result.register_benchmarks({'mmlu': mmlu})
result.save('./anna_llm_results')
Collecting calibration data in complex pipelines¶
For complex pipelines like diffusion models, collecting calibration data can be challenging.
The PipelineAnalyser class simplifies this by automatically capturing activations during pipeline execution.
Override run_pipeline_to_save_activations to generate calibration data for your target component.
In the SDXL example below, UNet activations are automatically saved and reused for analysis.
There is no need to provide train_dataloader or override unpack_batch when using PipelineAnalyser.
from qlip_algorithms.anna import PipelineAnalyser
from diffusers import StableDiffusionXLPipeline
import torch
# Load diffusion pipeline
pipeline = StableDiffusionXLPipeline.from_pretrained(
'stabilityai/stable-diffusion-xl-base-1.0',
torch_dtype=torch.float16,
device='cuda'
)
# Define SDXL analyser
class SDXLAnalyser(PipelineAnalyser):
def run_pipeline_to_save_activations(self):
prompts = ["A beautiful landscape", "A cat in space", ...]
for prompt in prompts: # Calibration prompts
self.pipeline(
prompt=prompt,
num_inference_steps=20,
height=1024,
width=1024
)
# Initialize and run analysis
analyser = SDXLAnalyser(
pipeline=pipeline,
bag_of_algorithms=bag,
component_name='unet', # Focus on UNet component
calibration_iterations=128,
calibration_data_path='./sdxl_calibration_data'
)
results = analyser.run(
min_constraint_value=0.5,
max_constraint_value=1.0,
num_configs=10,
constraint_type='size'
)
Limitations and Future Plans¶
Currently ANNA supports only constraints that may be expressed as a linear function of block parameters such as model size, MACs, etc. In the future we will add support for more complex constraints.
- ANNA: Automatic Neural Network Acceleration
- Overview
- API Reference
- Basic ANNA example
- Configure a bag of algorithms
- Select model blocks to be analysed
- Customizing input and output data preprocessing
- Constraints types
- Custom loss functions
- Running with distributed data parallel
- Evaluate and visualize results
- Model serialization and deserialization
- LLMs Analysis
- Collecting calibration data in complex pipelines
- Limitations and Future Plans