Quantization API¶
Attention
Access to Qlip requires an API token from the TheStage AI Platform and additional access, which can be requested by contacting frameworks@thestage.ai.
Overview¶
Note
The Qlip Quantization API provides a foundational framework for constructing custom quantization algorithms in Pytorch. It is intended primarily for simulation and training purposes, rather than direct inference. For deploying quantized models in production, use the Nvidia Compiler and Inference API module.
Not all quantization configurations are supported for inference, as compatibility depends on the target hardware and inference framework. To ensure proper deployment, use the pre-defined quantization configurations available in the Nvidia Compiler and Inference API module.
Direct application of this API to models is not recommended. For standard workflows, use the qlip.algorithms module, which offers pre-defined state-of-the-art quantization algorithms.
This API is best suited for building custom quantization solutions, debugging, or evaluating the inference-time and memory impact of various quantization configurations.
The Qlip Quantization Manager is a utility designed to handle the quantization process for Pytorch models. Quantization is a technique used to reduce the precision of the numbers used to represent a model’s parameters, which can lead to smaller model sizes and faster inference times, especially on hardware with limited computational resources. Combining with our Automated NNs Analyzer(ANNA) it provides a comprehensive solution for optimizing neural networks with full control of quality/model size and speed trade-off. It is particularly useful for deploying models on edge devices or in scenarios where computational efficiency is critical.
Why use Qlip Quantization?
Cases for using the Qlip Quantization API include:
Quantization algorithms development: The API provides a flexible framework for implementing custom quantization algorithms, allowing developers to experiment with different quantization strategies and configurations.
Research on model speed performance: Researchers can use the API to explore the effects of quantization together with Nvidia Compiler and Inference API on model performance, enabling them to develop new techniques for improving inference speed and reducing memory usage.
Research on model quality performance: Quick experimentation with different quantization schemes and parameters to evaluate your custom algorithms’ impact on model quality.
Model optimization: The API can be used to optimize existing models by applying quantization techniques, which can lead to significant improvements in inference speed and memory footprint. For standard workflows, it is recommended to use the qlip.algorithms module, which provides pre-defined state-of-the-art quantization algorithms.
Memory footprint reduction: By quantizing model parameters, the API helps reduce the memory footprint of models, making them more suitable for deployment on resource-constrained devices.
Inference speed improvement: Quantization can lead to faster inference times, especially on hardware that supports lower precision arithmetic, such as GPUs and specialized accelerators. On LLMs it usually leads to 1.5-2x speedup on Nvidia GPUs.
Integration with deploy package: The API is designed to work seamlessly with the Nvidia Compiler and Inference API module, allowing for easy deployment of quantized models on various hardware platforms, including NVIDIA GPUs and Apple Silicon devices.
Support matrix¶
The Qlip Quantization API supports a wide range of quantization techniques and configurations.
Note
“Hardware Support” indicates that the quantization API is compatible with the listed hardware platforms. However, this does not guarantee that a quantized model can be directly deployed on that hardware.
Data Type |
Bitwidths Supported |
Symmetric |
Asymmetric |
Hardware Support |
Qlip Nvidia Compiler Support |
|---|---|---|---|---|---|
int |
2 - 16 |
Yes |
Yes |
NVIDIA, AMD, CPU |
NVIDIA Turing, Ampere, Ada Lovelace, Hopper, Blackwell only symmetric |
uint |
2 - 16 |
Yes |
Yes |
NVIDIA, AMD, CPU |
NVIDIA Turing, Ampere, Ada Lovelace, Hopper, Blackwell only 8 bit through conversion to symmetric |
float |
8 ( |
Yes |
No |
NVIDIA Ada Lovelace, Hopper, Blackwell |
NVIDIA Ada Lovelace, Hopper, Blackwell |
Quantization protocol description¶
Quantization is the process of mapping real-valued data from a continuous domain to a finite discrete set. Formally, quantization is defined as a mapping from a real vector space to a finite subset:
where \(\rho\) is a metric (for example, Euclidean distance). When \(n = 1\), \(Q\) is called scalar quantization; for \(n > 1\), it is called vector quantization.
Tensor Quantization¶
Tensor quantization extends these ideas to multi-dimensional arrays (tensors):
a) Apply the scalar quantization function \(Q\) elementwise to each entry of the tensor, or apply vector quantization considering the tensor as a vector.
b) Split a tensor \(T\) into subtensors \(T_i\) of dimension \(k\) and apply \(Q\) to each subtensor (e.g., per-channel or per-group quantization).
Neural Networks Quantization¶
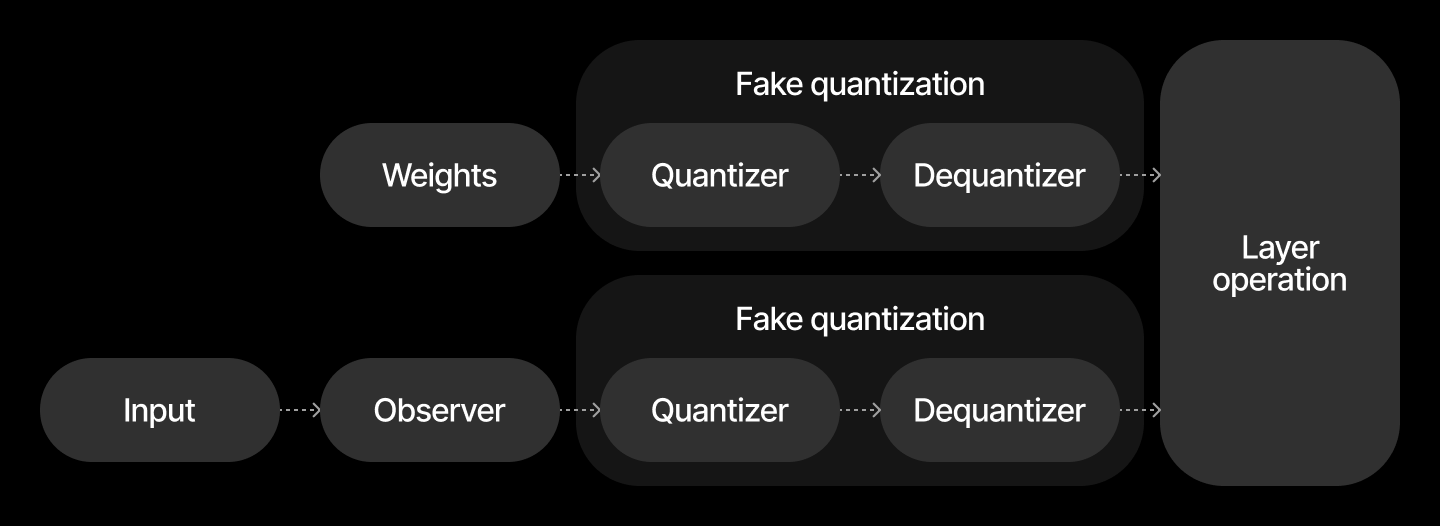
Quantizing neural networks typically involves replacing some or all tensors (such as weights and activations) with quantized or “fake-quantized” versions. For instance, to quantize a tensor ( T ) lying in an interval ([0, 1]) using an int8 grid ( G ):
where:
\(T_{fq}\) is the fake quantized tensor
\(T_q\) is the quantized tensor (integer values)
\(s\) is the quantization scale
\(t\) is the zero-point or quantization shift, or offset.
This approach allows efficient representation and computation using lower-precision data types.
Different Types of Quantization¶
Symmetric quantization: The shift parameter \(t = 0\).
Asymmetric quantization: The shift parameter \(t \neq 0\).
Per-tensor quantization: The scale parameter \(s\) is a scalar.
Per-channel quantization: The tensor is split by channels, and each channel has its own scale parameter (\(s\) is a vector of scales).
Per-group quantization: The tensor is split into groups, and each group has its own scale parameter (\(s\) is a vector of scales).
Quantized Matrix Multiplication¶
In quantized neural networks, weights and activations can be mapped to lower-precision representations (such as int8), enabling efficient computation. Assume we have two fake quantized matrices in int8 data type:
where:
\(W = s_w W_{\text{int8}}\) is the quantized weight matrix, with scale \(s_w\)
\(X = s_x X_{\text{int8}}\) is the quantized input matrix, with scale \(s_x\)
\(W_{\text{int8}}\), \(X_{\text{int8}}\) are the corresponding int8 representations
Matrix multiplication, being a linear operation, is performed as:
The main computation \((W_{\text{int8}} \times X_{\text{int8}})\) can be efficiently implemented as an integer matrix multiplication, and the floating-point scaling is applied afterwards.
Note
In practice, zero-point (offset) ( t ) for weights is often set to zero to avoid extra overhead.
Example: Int8 Quantization¶
Suppose the original (floating-point) weights and inputs are in ranges \([w_{\min}, w_{\max}]\) and \([x_{\min}, x_{\max}]\), and we want to quantize them to int8 (\([-128, 127]\)):
Compute the scales:
\[s_w = \frac{w_{\max} - w_{\min}}{255} \qquad s_x = \frac{x_{\max} - x_{\min}}{255}\]Quantize:
\[ \begin{align}\begin{aligned}W_{\text{int8}} = \text{round}\left(\frac{W - w_{\min}}{s_w}\right) - 128\\X_{\text{int8}} = \text{round}\left(\frac{X - x_{\min}}{s_x}\right) - 128\end{aligned}\end{align} \]Integer matrix multiplication is performed on \(W_{\text{int8}}\) and \(X_{\text{int8}}\), followed by rescaling using \(s_w s_x\).
Weights-Only and Weights+Activations Quantization¶
There are two principal approaches to quantization in deep learning layers:
Weights-Only Quantization
Only the model weights are quantized; inputs/activations remain in higher precision (e.g., FP32 or FP16). This scheme is often used for efficient inference with minimal accuracy loss.
Quantization of Both Weights and Activations
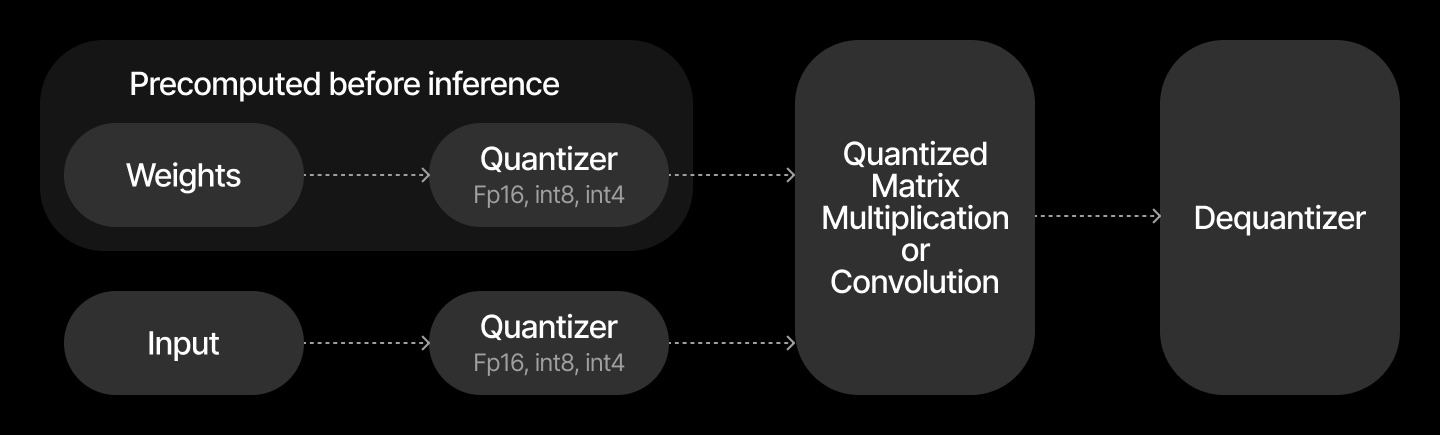
Both weights and input activations are quantized, so the matrix multiplication operates entirely in low precision (e.g., int8), maximizing performance.
Note
For weight-only quantization, dequantization is performed before the matrix multiplication.
For full quantization, both operands are quantized and scaling is applied after integer multiplication.
Quantization Aware Training (QAT)¶
Quantization-aware training (QAT) simulates quantization effects during neural network training, allowing models to adapt to the reduced precision. However, the quantization function itself is non-differentiable, which poses a challenge for gradient-based optimization.
To address this, QAT typically employs the straight-through estimator (STE). During the forward pass, quantization is applied as usual:
where \(Q\) denotes the quantization function. During the backward pass, the STE simply copies the gradient from the quantized value back to the input as if the quantization operation were the identity function:
This approximation allows standard backpropagation to proceed, enabling effective training despite the presence of non-differentiable quantization steps.
Note
STE is widely used in QAT frameworks, but it may introduce bias in the gradient estimation. Nevertheless, it remains a simple and effective approach for enabling end-to-end training with quantized operations.
Qlip quantization protocol overview¶
Qlip quantizers can be configured to apply various quantization techniques, including:
Qlip Quantization Possibilities
Dynamic Quantization: Scale and offset are estimated during inference, allowing for flexible quantization without pre-computed parameters.
Static Quantization: Scale and offset are pre-computed during calibration, leading to potentially better speed performance.
Weight only Quantization: Only the model weights are quantized, while inputs/activations remain in higher precision.
Different quantization granularity: Options include per-tensor, per-channel, per-group, per-token (for transformers).
Integer quantization: Supports various bit-widths (e.g., 2-16 bits) for weights and activations.
Floating point quantization: Supports
float8_e4m3fnfor weights and activations.Symmetric and Asymmetric Quantization: Options for symmetric (zero-point = 0) and asymmetric quantization (zero-point != 0).
Attention quantization: Special handling for attention layers in transformer models.
QAT (Straight-Through Estimation): QAT (quantization-aware training), allowing gradients to flow through quantized operations.
Qlip quantizers has the following structure:
Qlip Quantizer
Quantization scheme: Defines: number of bits, data type (int, float), and whether the quantization is symmetric or asymmetric.
Granularity: Specifies how quantization is applied (per-tensor, per-channel, etc.).
Quantization mode: Determines whether quantization is dynamic or static.
Observer: Collects statistics during calibration to compute scale and zero-point for static quantization.
Scale and zero-point: Parameters used to convert between quantized and floating-point representations.
Round function: Defines how values are rounded during quantization, can be customized.
API Reference¶
Quantization API provides a high-level interface for quantizing Pytorch models. It supports various quantization techniques, including dynamic and static quantization, and allows for easy integration with existing Pytorch workflows.
- class QuantizationManager¶
The main class for managing the quantization process of Pytorch models.
- setup_modules(self, modules, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-channel', activations_scheme=QuantScheme('int', 8, False), activations_granularity='per-batch', quantization_mode='static', calibration_iterations=1, train_activations_scale=False, train_activations_offset=False, train_weights_scale=False, train_weights_offset=False, observer=None, observer_kwargs={})¶
Applies quantization to the model.
Parameters
modules (
List[torch.nn.Module]): List of Pytorch modules to apply quantization.weights_scheme (
Union[QuantScheme, Dict[str, Any]]): Scheme for quantizing weights (default is 8-bit integer).weights_granularity (
Union[str, QuantGranularity, Dict[str, Any]]): Granularity for weight quantization (default is per-channel).activations_scheme (
Union[QuantScheme, Dict[str, Any]]): Scheme for quantizing activations (default is 8-bit integer).activations_granularity (
str): Granularity for activation quantization (default is per-batch).placement (
str): Specifies where to apply quantization (input, output, or attention).quantization_mode (
str): Mode of quantization (static or dynamic).calibration_iterations (
int): Number of iterations for calibration activations scale and offset. (default is 1).train_activations_scale (
bool): Whether to train the scale of activations.train_activations_offset (
bool): Whether to train the offset of activations.train_weights_scale (
bool): Whether to train the scale of weights.train_weights_offset (
bool): Whether to train the offset of weights.observer (
Optional[BaseObserver]): Observer for collecting statistics during quantization.observer_kwargs (
Dict[str, Any]): Additional keyword arguments for the observer.weights_scale_offset_dtype (
torch.dtype): Data type for weights scale and offset parameters (default istorch.float32).activations_scale_offset_dtype (
torch.dtype): Data type for activations scale and offset parameters (default istorch.float32).
- class qlip.base.observers.StatMinMaxObserver(dim=None)¶
The main class for managing the quantization process of Pytorch models.
Parameters
dim (
Optional[int]): Dimension along which to compute the minimum and maximum values. If None, computes over all dimensions.
- get_stats(self)¶
Applies quantization to the model.
Returns
stats (
Tuple[torch.Tensor]): A tuple containing the minimum and maximum statistics collected by the observer.
Quantizing Pytorch models¶
In this section, we will explore how to apply quantization to Pytorch models using the Qlip Quantization API. It not covers any specific algorithm or quality related aspects, but rather focuses on the API usage and how to apply quantization to Pytorch models. Algorithms and quality related aspects are covered in the Quantization Algorithms module.
Minimal example of quantizing Pytorch models¶
Lets consider a simple example of quantizing Linear and Conv2d layers in a Pytorch model to int8:
import torch
from qlip.quantization import QuantizationManager
from qlip.quantization import QuantScheme, QuantGranularity
# Define a simple model
class SimpleModel(torch.nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = torch.nn.Linear(10, 20)
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=3)
def forward(self, x):
x = self.fc1(x)
x = self.conv1(x.unsqueeze(0).unsqueeze(0))
return x
model = SimpleModel()
Now we can apply quantization to the model using the QuantizationManager:
# Initialize the quantization manager
quant_manager = QuantizationManager()
# Apply quantization to the model
quant_manager.setup_modules(
[
module for module in model.modules()
if isinstance(module, (torch.nn.Linear, torch.nn.Conv2d))
],
# symmetric quantization for weights
weights_scheme=QuantScheme("int", 8, symmetric=True),
weights_granularity="per-channel",
# asymmetric quantization for activations
activations_scheme=QuantScheme("int", 8, symmetric=False),
quantization_mode="static",
# number of iterations for calibration
# to estimate activation scale and offset
calibration_iterations=1,
)
print("Quantized model:", model)
Output on the console:
Quantized model: SimpleModel(
(fc1): ParametrizedLinear(
in_features=10, out_features=20, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): WeightsQuantizer(scheme=int8, granularity=per-channel(axis=0))
)
)
(activations_quantizer): ActivationsQuantizer(scheme=int8, mode=static)
)
(conv1): ParametrizedConv2d(
1, 16, kernel_size=(3, 3), stride=(1, 1)
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0): WeightsQuantizer(scheme=int8, granularity=per-channel(axis=0))
)
)
(activations_quantizer): ActivationsQuantizer(scheme=int8, mode=static)
)
)
In a case of static quantization you need to intialize quantization parameters by running the model on some input data:
# Example input for Linear layer
input_data = torch.randn(1, 10)
# as calibration is set to 1, we just need to run the model once
model(input_data)
Note
Setting up calibration_iterations to a value greater than 1 allows for more robust estimation of activation scales and offsets,
especially in cases where the input data has a wide range of values. Its recommended to use a representative dataset for calibration
to ensure accurate quantization parameters. On paractice, values of 64-1024 are often used for calibration iterations, depending on the model and dataset.
Quantization can be applied to any PyTorch module; however, weight quantization is only performed on the module’s weight parameter.
Activation quantization is applied to either the input or output of the module, depending on the placement parameter.
Note that, in such cases, the resulting quantization may not be mathematically precise or supported by the target hardware.
Integer quantization¶
Qlip supports integer quantization for weights and activations using various bit-widths (e.g., 2-16 bits). Round function for integer quantizartion is set to “round” by default. Custom round functions will be supported in future releases. To setup desired bit-widths you just need to specify it in the QuantScheme:
# Apply quantization to the model with 4-bit weights and 8-bit activations
quant_manager.setup_modules(
[
module for module in model.modules()
if isinstance(module, (torch.nn.Linear, torch.nn.Conv2d))
],
weights_scheme=QuantScheme("int", 4, symmetric=True),
weights_granularity="per-channel",
activations_scheme=QuantScheme("int", 8, symmetric=False),
quantization_mode="static",
calibration_iterations=1,
)
Floating point quantization¶
Floating point quantization is also supported, specifically the float8_e4m3fn format.
Other bit-widths currently are not supported. To apply floating point quantization,
you can use the QuantScheme with the float8 scheme:
# Apply quantization to the model with float8 weights and activations
quant_manager.setup_modules(
...
weights_scheme=QuantScheme("float", 8, symmetric=True),
weights_granularity="per-channel",
activations_scheme=QuantScheme("float", 8, symmetric=False),
quantization_mode="static",
calibration_iterations=1,
)
For float quantization, the round function is deault cast operation in Pytorch.
Compilation for Nvidia GPUs¶
To compile quntized models for Nvidia GPUs, you need to use the Nvidia Compiler and Inference API module.
You can pass pre-defined quantization schemes like NVIDIA_INT_W8A8, NVIDIA_FLOAT_W8A8, NVIDIA_INT_W4WO to the qlip.quantization.QuantizationManager:
import qlip
from qlip.quantization import QuantizationManager
from qlip.deploy.nvidia import NVIDIA_INT_W8A8, NVIDIA_FLOAT_W8A8, NVIDIA_INT_W4WO
# Define the quantization scheme
quant_scheme = "NVIDIA_INT_W8A8"
# Create a builder configuration with the quantization scheme
model = ... # Your Pytorch model
quantizer = QuantizationManager()
quantizer.setup_modules(
[
module for module in model.modules()
if isinstance(module, (torch.nn.Linear, torch.nn.Conv2d))
]
calibration_iterations=1,
**NVIDIA_INT_W8A8
)
# Initialize quantization ranges
model(input)
Now setup the compiler and compile the model:
from qlip.deploy.nvidia import NvidiaBuilderConfig
builder_config = NvidiaBuilderConfig(
quantization_scheme=quant_scheme,
# For int8 quantization
builder_flags={"FP16", "INT8"}
)
# Compile the model with the quantization scheme
model_qlip = qlip.compile(
model, dynamic_shapes="range",
builder_config=builder_config
)
# trace the example input
model_qlip(input)
model_qlip.compile()
To setup builder_flags for other quantization schemes, refer to the Nvidia Compiler and Inference API documentation.
Compiler transforms the model with fake quantization for inference. In the case of weights and activations quantization it transforms it as follows:
In the case of weights only quantization transformation looks like this:
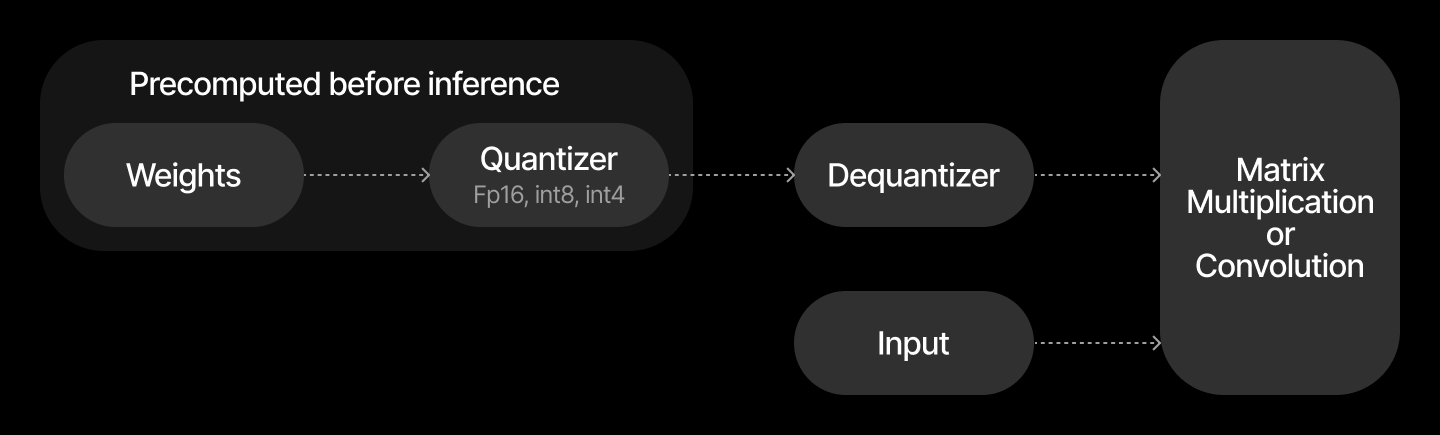
Efficient implementations can fuse the dequantization of weights directly into the main operation, reducing memory usage and improving inference speed.