Nvidia Compiler and Inference API¶
Attention
Access to Qlip requires an API token from the TheStage AI Platform and additional access, which can be requested by contacting frameworks@thestage.ai.
Here we we will cover the following topics:
Overview¶
Main pipeline for compiling and running inference of Pytorch models on NVIDIA GPUs with Qlip:
Compilation workflow
Step 1: Importing Required Modules and Model Preparation
Import
qlipmodule to useqlip.compile(),qlip.deploy.nvidia.NvidiaBuilderConfig.Create a PyTorch model and move it to the desired device (e.g., GPU).
Select blocks for compilation. Can use the whole model.
Step 2: Configuring the Builder
Specify builder flags (e.g., data types
FP16,BF16,INT8,FP8).
Step 3: Wrapping the Model for Compilation
Use
qlip.compile()to wrap the model for compilation.Specify dynamic shapes for inputs (e.g., “range” for minimum and maximum shapes).
Pass the builder configuration to the compile function.
Step 4: Tracing the Model and Compilation
Trace the model with example inputs to capture dynamic shapes.
Compile the model/blocks with
model.compile().
Step 5: Saving and Running Inference
Save the compiled model to a file for fast cold start.
Run inference of the compiled model as you would with the original PyTorch model.

Why to use Qlip compiler?
Significant acceleration of inference on NVIDIA GPUs.
Not JIT compilation. Compiled models can be saved to disk and reused with minimal cold start time.
Support of dynamic shapes and optimization for specific performance critical inputs.
Allows to mix PyTorch code and multiple compiled models in a single pipeline with full memory reusage.
Natively supports compilation of models with quantized weights and activations produced by Quantization API and Quantization Algorithms.
Supports compilation of models by blocks, allowing to optimize specific parts of the model separately and reduce memory usage during compilation.
Supports compilation of models to
float32,float16andbfloat16data types.Supports compilation of mixed-precision models mixing w8a8, w4a16, w16a16 and
float16,bfloat16data types.
API Reference¶
Compiler API provides a high-level interface for compiling and optimizing Pytorch models for deployment on NVIDIA hardware. It supports various configurations and optimizations to ensure efficient inference. Compiler based on TensorRT, CUDA libraries and custom TheStage AI kernels.
Note
Compiler supports TenssorRT 10.10 and higher versions. It can be used with TensorRT 10.1 - 10.9, but can require additional configuration, so it is not recommended to use it with these versions.
Compiler API¶
- qlip.compile(model: Optional[Callable] = None, dynamic_shapes='none', builder_config: NvidiaBuilderConfig = None, runner_config: NvidiaSessionConfig = None, verbosity='error', group: str = 'default')¶
Wraps a PyTorch model for compilation and inference on NVIDIA GPUs.
Parameters
model (torch.nn.Module): PyTorch model to be compiled.
dynamic_shapes (str): Specify type of possible inputs. Can be “none”, “range” or “list” of static shapes. “none” means that model will be compiled with static shapes. “range” means that model will be compiled with dynamic shapes, and it will use minimum and maximum shapes during tracing. List of static shapes means that model will be compiled with static shapes.
builder_config (
qlip.deploy.nvidia.NvidiaBuilderConfig, optional): Configuration for the builder. Can be used to specify data types, optimization flags, etc.runner_config (
qlip.deploy.nvidia.NvidiaSessionConfig, optional): Configuration for the runner. Can be used to specify session settings, such as batch size, max workspace size, etc.verbosity (str): Logging verbosity level. Default is “error”.
group (str): Group name for the compiled model. Default is “default”.
Returns
qlip.deploy.compiler.QlipCompiledModule: Wrapped module for compilation.
Compiled module API¶
- class qlip.deploy.compiler.QlipCompiledModule¶
A wrapper for compiled PyTorch models. It allows to run inference on the compiled model and provides methods to save and load the compiled model.
Warning
This class is not intended to be used directly. Use qlip.compile to create an instance of this class.
- compile(device: str = 'cuda')¶
Compile the Pytorch module. Run this method after tracing the model with example inputs.
Parameters
device (
str, optional): Device to compile the model on. Default is “cuda”.
- save(path: str)¶
Save the compiled model to a file.
Parameters
path (
str): Path to save the compiled model.
- load(path: str, device: str = 'cuda')¶
Load the compiled model from a file. Call this method after wrapping the model with qlip.compile.
Parameters
path (
str): Path to load the compiled model from.device (
str, optional): Device to load the model to. Default is “cuda”.
- class qlip.deploy.COMPILE_REGISTRY¶
A registry for compiled modules. Its global variable that holds all compiled modules. It reasonable to use when you wrapping blocks for compilation in a loop and then need to compile them all at once. Also, it allows to use PyToorch default memory pool and reuse memory for compiled modules.
Warning
Global registry would be replaced by
NvidiaCompilerclass in the future.- compile(group: str = 'default')¶
Register a compiled module by name.
Parameters
group (
str, optional): Group name for the compiled module. Default is “default”.
- allocate_device_memory(group: str = 'default')¶
Allocate memory for the compiled module.
Parameters
group (
str, optional): Group name for the compiled module. Default is “default”.
- clear(group: str = 'default')¶
Delete all compiled modules in the registry and deallocates memory for the compiled module. Its important to call this if you wish to free all memory for compiled modules.
Parameters
group (
str, optional): Group name for the compiled module. Default is “default”.
Compiler configuration¶
- class qlip.deploy.nvidia.NvidiaBuilderConfig(builder_flags, io_dtype_per_tensor=None, normalization_dtype=None, builder_optimization_level=3, profiling_verbosity=None, avg_timing_iterations=1, timing_cache=b'', rewrite_timing_cache=False)¶
Holds configuration options for the Nvidia builder.
Parameters
builder_flags: (
set[str]) - A list of flags that can be used to control the builder’s behavior. Each flag should be one of thetrt.BuilderFlagenum options, such as “FP16” or “INT8” for mixed precision or integer precision mode, by default an empty list.io_dtype_per_tensor: (
dict, optional): Specifies the data type of the input and output tensors, per tensor.It supports “FP16” or “BF16”. When set, the I/O tensors will be cast to the specified type. When equal to base, the type is deduced from builder_flags, by default an empty dictionary.normalization_dtype: (
str, optional): Specifies the precision of the normalization layer. It supports “FP16” or “BF16”. When set, the normalization layer will be cast to the specified type. When equal to base, the type is deduced from builder_flags, by default None (which means FP32).builder_optimization_level: (
int): Controls the optimization level (1-5) of the engine build. Higher values can enable more aggressive optimizations for performance, but may result in longer build times, by default 3.profiling_verbosity: (
str, optional): Sets the verbosity of profiling information during engine building. Supported values are “none”, “default”, and “detailed”, which control the level of logging, by default None.avg_timing_iterations: (
int): Specifies the number of iterations used to average the timing results when building the engine. This can help to improve the accuracy of the timing results, by default 1.timing_cache: (
Union[str, bytes]): Path to the timing cache file or serialized timing cache. If provided, the builder will use the timing cache to speed up engine building, by default b””.output_timing_cache. (
str): Path to save the timing cache file. If provided, the timing cache will be saved to the specified path after engine building, by default “”.rewrite_timing_cache (
bool): If True, the timing cache file will be rewritten with the updated timing cache, by default False.
Inference configuration¶
- class qlip.deploy.nvidia.NvidiaSessionConfig(stream: Optional['torch.cuda.Stream'] = None, weight_streaming_budget_v2: int = - 1)¶
Configuration for Inference Session.
Parameters
stream (
torch.cuda.Stream, optional): CUDA stream for execution.weight_streaming_budget_v2 (
int, optional): Weight streaming budget. If 0, stream all weights. Set value in bytes.
PyTorch Model Compilation and Inference¶
Here we will cover how to compile and run inference of PyTorch models on NVIDIA GPUs using Qlip:
Basic model compilation¶
First scenario is simple. We have Resnet-18 model and wish to use it for image classification. We wish to support inference on different batch size from 1 to 64. We will:
Use
float16data type for original model.Wrap model with
qlip.compileto compile it for NVIDIA GPUs.Specify input shapes as dynamic range.
Trace model with 2 example inputs to capture dynamic shapes.
Compile the model with
model.compile().Compare inference time of original and compiled models.
Here is the code to do that:
import qlip
import torch
import torchvision.models as models
from qlip.deploy.nvidia import NvidiaBuilderConfig
# select fastest device by default
device = qlip.node.device
dtype = torch.float16
# creating models for compilation and comparison
model_orig = models.resnet18(pretrained=True).to(device).to(dtype)
model_qlip = models.resnet18(pretrained=True).to(device).to(dtype)
model_orig.eval()
model_qlip.eval()
# different input for tracing
input_1 = torch.randn(1, 3, 224, 224).to(device).to(dtype)
input_2 = torch.randn(64, 3, 224, 224).to(device).to(dtype)
# wrapping model for compilation
model_qlip = qlip.compile(
model_qlip,
# specify dynamic input shapes strategy
# "range" will use minimum and maximum shapes during tracing
dynamic_shapes="range",
# force compilation to use float16 data type
builder_config=NvidiaBuilderConfig(
builder_flags={"FP16"}
)
)
To compile model with different input shapes, you can use dynamic shapes strategy. For that we need to trace model with different input shapes. Using to inputs with batch size 1 and 64 and then compile model with dynamic shapes strategy we will be able to run inference on any input shape with batch size between 1 and 64.
# trace different input shapes which we wish to conver
model_qlip(input_1)
model_qlip(input_2)
model_qlip.compile()
Now we can run inference on any input shape with batch size between 1 and 64 and compare results with original model.
import time
input_3 = torch.randn(32, 3, 224, 224).to(device).to(dtype)
def benchmark(model, input, n_repeat=10):
t = time.time()
qlip.node.backend.synchronize()
with torch.no_grad():
for i in range(n_repeat):
output = model(input)
qlip.node.backend.synchronize()
return time.time() - t, output
t_qlip, output_qlip = benchmark(model_qlip, input_3)
t_orig, output_orig = benchmark(model_orig, input_3)
print("DIFF: ", (output_qlip - output_orig).abs().median())
print(f"Qlip model inference time: {t_qlip:.4f} seconds")
print(f"Original model inference time: {t_orig:.4f} seconds")
Output on Nvidia L40s GPU:
DIFF: tensor(0.0020, device='cuda:0', dtype=torch.float16)
Qlip model inference time: 0.0142 seconds
Original model inference time: 0.0760 seconds
If initial model uses bfloat16 data type, we can specify it in the builder configuration:
model_qlip = qlip.compile(
model, dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"BF16"}
)
)
If model uses float32 data type, we don’t need to specify it in the builder configuration, as it is default data type:
model_qlip = qlip.compile(
model, dynamic_shapes="range"
)
To delete compiled model and free memory, you can use:
del model_qlip
qlip.deploy.compiler.COMPILE_REGISTRY.clear()
Serialization of Compiled Models¶
After compilation, you can save the compiled model to a file for fast cold start. To save the compiled model, you can use the save method of the QlipCompiledModule class. This will serialize the model and save it to the specified file path. Here is the code to do that:
model_qlip.save("compiled_resnet18.qlp")
To load the compiled model from a file, you can use the load method of the QlipCompiledModule class.
This will deserialize the model and load it into memory. Currently we need to wrap model model with qlip.compile
to create a compiled model object and then load it from the file. But in that case we do not need to trace the model again
and call compile() method, as it will use the saved compiled model directly:
model_qlip = qlip.compile(
model_qlip, dynamic_shapes="range"
)
model_qlip.load("compiled_resnet18.qlp")
Multiple data types in inputs¶
Considering previous example, we can specify the data type of inputs during compilation.
Lets say we want to use float32 for part of inputs and float16 for the rest.
For instance, we have precision sensitive operation that should be in float32,
then it can casted to float16 and used in the rest of the model. Such case can be automatically handled by Qlip.
On practise, such situation happen in FLUX model, when we keep rotatary embeddings in float32.
Test model with multiple inputs and different data types:
class MultiInputModel(torch.nn.Module):
def forward(self, scale, input_1, input_2):
input_1 = torch.sigmoid(input_1*scale).to(input_2.dtype)
return input_1 + input_2.unsqueeze(-1).unsqueeze(-1)
Model compilation and comparison with original model:
import qlip
import torch
from qlip.deploy.nvidia import NvidiaBuilderConfig
device = qlip.node.device
dtype = torch.float16
model = MultiInputModel().to(device).to(dtype)
model_qlip = qlip.compile(
model, dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"FP16"}
)
)
# Trace with dictionary inputs
input_1 = torch.randn(1, 16, 64, 64).to(device).to(torch.float32),
input_2 = torch.randn(1, 16).to(device).to(dtype)
scale = torch.tensor(0.001).to(device).to(torch.float32)
# Trace model with example inputs
model_qlip(scale, input_1, input_2)
model_qlip.compile()
# Run inference with compiled model
output = model_qlip(scale, input_1, input_2)
Working with multiple shapes¶
We already saw how to compile model with dynamic shapes, but there are few more options to specify input shapes. There three options generally to specify input shapes:
Range-based dynamic shapes: Use minimum and maximum shapes observed during tracing.
List of fixed shapes: Use a list of shapes that were observed during tracing. This is useful when you have a fixed set of shapes that you want to support with maximum performance.
Mix of both: Use list of fixed shapes for performance critical shapes and range-based for others.
Case of dynamic shapes
We already saw how to compile model with dynamic shapes. When you specifying dynamic_shapes="range"
it means that model will be compiled with dynamic shapes. When you trace the model with different shapes,
it will use minimum and maximum shapes observed for each axes during tracing.
# Compile with dynamic shapes
model_qlip = qlip.compile(
# Use min/max observed during tracing
model_qlip, dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"FP16"}
)
)
# Trace with different shapes
model_qlip(input_1)
model_qlip(input_2)
...
model_qlip.compile()
List of fixed shapes
If you have a fixed set of shapes that you want to support with maximum performance, you can use a list of shapes.
For that you need to specify dynamic_shapes="list" and trace all example inputs with all shapes you want to support.
# Compile with list of shapes
model_qlip = qlip.compile(
model_qlip, dynamic_shapes="list",
builder_config=NvidiaBuilderConfig(
builder_flags={"FP16"}
)
)
# Trace with different shapes
model_qlip(torch.randn(1, 3, 224, 224).to(device).to(dtype))
model_qlip(torch.randn(4, 3, 224, 224).to(device).to(dtype))
model_qlip(torch.randn(8, 3, 224, 224).to(device).to(dtype))
...
model_qlip.compile()
In the case above, we traced the model with three different shapes. Note that model will work only with these shapes. You can do the same for model with multiple inputs. Take into account that it will take additional time for compilation.
Compilation of Quantized Models¶
First of all not all quantization configurations are supported by Nvidia GPUs. These are types of quantization which are supported by Nvidia:
Supported quantization types
w8a8(both weights and activations are quantized)Quantization with
int8data types for linear and convolution layers. Supports for almost all NVidia GPUs from Turing to Blackwell architecture. For instance, RTX 2060, RTX 2080, RTX 3090, A100, L40s, H100, B200 are supported.
w8a8quantization withfloat8_e4m3fnfor linear and convolution layers.This is a new quantization type that is supported by Nvidia GPUs starting from Ada Lovelace architecture. For instnace, GPUs: L40s, RTX 4090, H100, H200, B200 are supported.
w4a16block quantization of weights withint4data type and no quantization of activations.This type of quantization helps to reduce memory usage in a case of large model and also accelerate inference sometimes for small batches, when weights memory transfer takes significant part of an inference time.
w4a4withfloat4data type.Supported starting from Nvidia Blackwell. Will be supported by qlip in a next release.
To quantize models with a listed types we can use pre-defined configurations for qlip.quantization.QuantizationManager:
Predefined quantization configurations for Nvidia
NVIDIA_INT_W8A8- for staticw8a8quantization withint8data type.NVIDIA_FLOAT_W8A8- for staticw8a8quantization withfloat8data type.NVIDIA_INT_W4WO- for weight only quantization withint4data type.NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC- for dynamic per-tokenw8a8quantization withint8data type.NVIDIA_FLOAT_W8A8_PER_TOKEN_DYNAMIC- for dynamic per-tokenw8a8quantization withfloat8data type.
Also we need to pass additional flags to qlip.deploy.nvidia.NvidiaBuilderConfig:
Builder flags for quantization
For
w8a8withint8-builder_flags={"FP16", "INT8"}. If base type isbfloat16, then usebuilder_flags={"BF16", "INT8"}.For
w8a8withfloat8-builder_flags={"FP16", "FP8"}. If base type isbfloat16, then usebuilder_flags={"BF16", "FP8"}.For
w4a16not required any additional flags.
Lets quantize model with w8a8 quantization using int8 data type.`
For quantized inference we need to quantize weights and activations in linear and convolution layers.
from qlip.quantization import QuantizationManager
from qlip.deploy.nvidia import NVIDIA_INT_W8A8, NVIDIA_FLOAT_W8A8, NVIDIA_INT_W4WO
device = qlip.node.device
dtype = torch.bfloat16
# initilize model
model = create_my_model().to(device).to(dtype)
# Prepare quantization wrapper
quantizer = QuantizationManager()
# Select modules to quantize (Linear in this case)
modules = [
mod for mod in gated_mlp.modules()
if isinstance(mod, torch.nn.Linear)
]
quantizer.setup_modules(
modules,
# quantizing each row of weights separately
weights_quantization="per-channel",
# number of batches for calibration of quantization ranges
n_init_batches=1,
# Predefined quantization parameters for NVIDIA INT8 W8A8
**NVIDIA_INT_W8A8
)
# run calibration to estimate activation ranges
model(input)
model.eval()
Now we can compile this quantized model with Qlip compiler:
from qlip.deploy.nvidia import NvidiaBuilderConfig
# Compile quantized model
model_qlip = qlip.compile(
model,
dynamic_shapes="range",
# if you have used NVIDIA_FLOAT_W8A8 you need to pass "FP8" flag
# instead of "INT8" in builder flags
builder_config=NvidiaBuilderConfig(
builder_flags={"BF16", "INT8"}
)
)
# Trace with example inputs
model_qlip(input)
model_qlip.compile()
# Run inference
output = model_qlip(input)
Model Compilation by Blocks¶
There are cases when we want to compile only specific parts of the model. For instance:
Its hard to trace graph of the whole model as it contains unsupported operations.
Its hard to compile the whole model due to memory limitations.
Mix
int8andfloat8data types in the model.
At the same time we are facing the problem that each compiled module requires its own memory for execution. Qlip solves this problem in a two ways:
Memory allocation strategies
Dynamic allocation of memory for compiled modules from Pytorch memory pool. This is straightforward and works well for most cases, but can lead to memory fragmentation.
Static allocation using global registry of compiled modules, which allows to reuse memory for compiled modules.
qlip.deploy.COMPILE_REGISTRYallocates single contiguous memory block for all compiled modules in the registry. But it can require manual memory deallocation if you want to free memory after inference of all compiled modules and run inference of another Pytorch models in the same process.
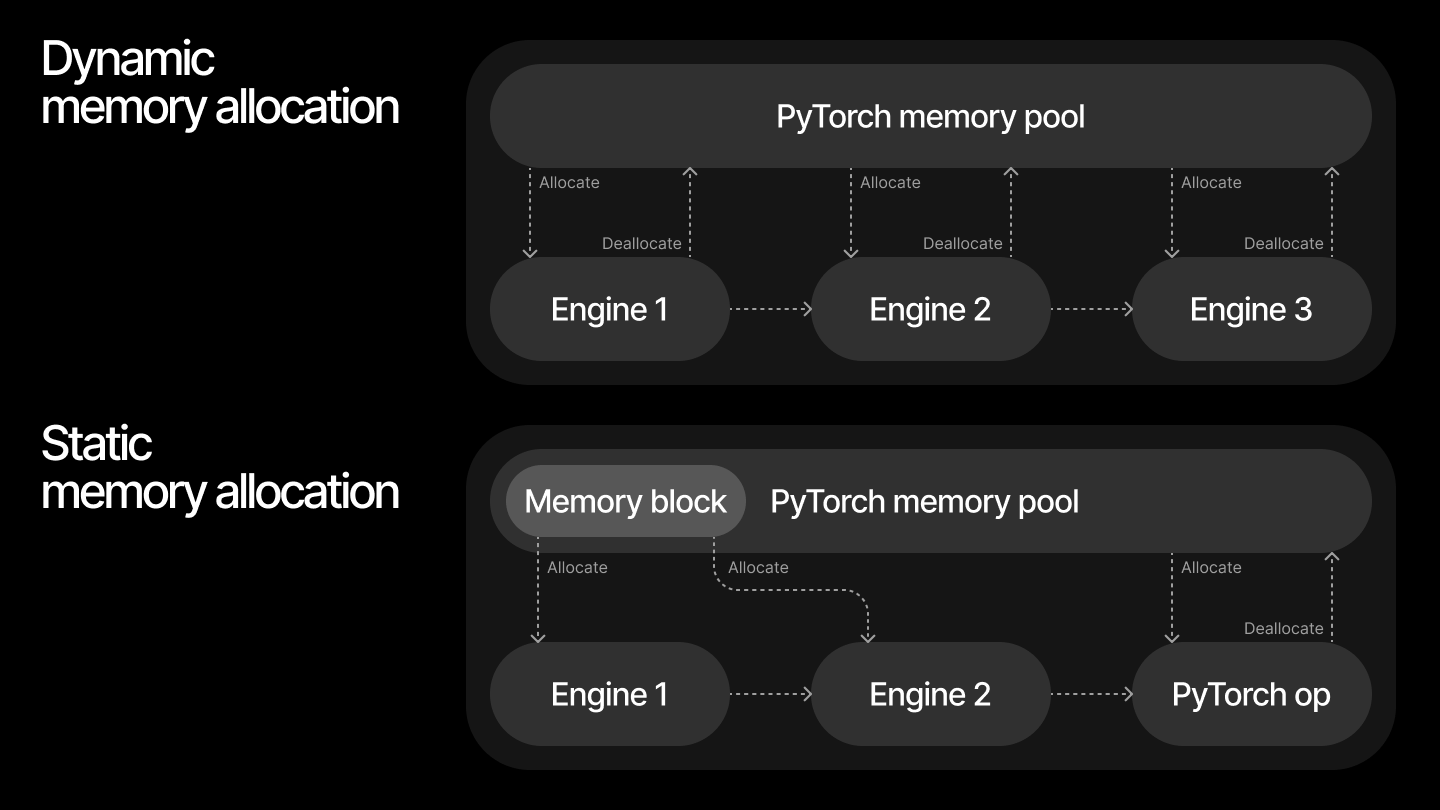
When comparing the two approaches for handling maximum possible input sizes, dynamic memory allocation typically results in higher overall memory usage. This is because memory is returned to the pool with some delay, and subsequent blocks may allocate additional memory before the previous memory is fully released. Additionally, running inference on varying input sizes can cause memory fragmentation.
In contrast, static memory allocation enables more efficient memory reuse across compiled modules, reducing total memory consumption. The Qlip memory manager analyzes the input, output, and intermediate tensors of all compiled modules and allocates a single contiguous memory block to accommodate them.
Lets imagine that we wish to compile 2 blocks in the model separately:
import torch
import qlip
from qlip.deploy.nvidia import NvidiaBuilderConfig
from qlip.deploy import COMPILE_REGISTRY
...
model.block_1 = qlip.compile(
model.block_1,
dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"BF16"}
)
)
model.block_2 = qlip.compile(
model.block_2,
dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"BF16"}
)
)
# tracing model with example inputs
model(input_1)
model(input_2)
# Compile both blocks
COMPILE_REGISTRY.compile()
# Run inference on both blocks
output = model(input_3)
If we wish to use the same memory for compiled blocks we need to allocate it through registry:
COMPILE_REGISTRY.compile()
COMPILE_REGISTRY.allocate_device_memory()
output = model(input_3)
Troubleshooting and Limitations¶
This section covers common issues and limitations when using Qlip for model compilation and inference on NVIDIA GPUs:
Handling input tuples, dictionaries and shape tensors¶
Warning
Qlip does not support dictionary inputs for compilation and inference. Tuples are partially supported and are not recommended to use.
Model can accept multiple inputs as arguments and keyword arguments. Non tensor inputs would be interpreted as constant values. Integers passed in a tuple would be interpreted as shape tensors.
The following example will work correctly:
import qlip
import torch
class MultiInputModel(torch.nn.Module):
def forward(self, input_1, input_2, shape):
input_2 = input_2.reshape(*shape)
return input_1 + input_2
model = MultiInputModel().to(qlip.node.device)
# Setting up compilation
model_qlip = qlip.compile(
model, dynamic_shapes="range"
)
input_1 = torch.randn(1, 16, 64, 64).to(qlip.node.device)
input_2 = torch.randn(1, 16).to(qlip.node.device)
shape = (1, 16, 1, 1)
model_qlip(input_1, input_2, shape)
model_qlip.compile()
model_qlip(input_1, input_2, shape)
Inference on different Nvidia GPUs¶
Compiled model can be used only on the same GPU it was compiled for. To run inference on a different GPU, you need to compile the model again on that GPU.
TensorRT supports compilation to use single engine on multiple GPUs, but we have found that it leads to significant performance degradation.
Cross-TensorRT version inference¶
Qlip also not supports inference of compiled models on different TensorRT versions. It is necessary to compile the model with the same TensorRT version as the one used for inference. We also have tested TensorRT feature to load engine with different TensorRT versions, but it leads to significant performance degradation and is not recommended to use.
Wrong shapes¶
When encountering shape-related error ValueError: Invalid input shape: no optimization profile defined for the given input shapes.
during inference, it usually means that the model was not compiled with the correct dynamic shapes or the input shapes do not match the expected shapes.
Moving models between GPUs on single machine¶
Currentlu Qlip does not support moving compiled models between different GPUs. You can specify device during compilation or model load.
model_qlip = qlip.compile(
model, dynamic_shapes="range",
builder_config=NvidiaBuilderConfig(
builder_flags={"FP16"}
),
device="cuda:0"
)
# or on model loud
model_qlip.load("compiled_model.qlp", device="cuda:0")
Out of memory errors¶
When encountering OOM errors during compilation it can be caused by several reasons:
Common causes of OOM errors
Large model size: The model is too large to fit into the available GPU memory. In this case, you can try to compile the model by blocks.
Specific kernels: Some operations in the model require more memory than others, leading to OOM errors.
Sometimes it can be caused because TensorRT tries to profile kernels with float32 data type,
even if builder flags specify float16 or bfloat16. In this case you can try to force compiler use
strongly typed kernels by specifying creation_flags:
from qlip.deploy.nvidia import NvidiaBuilderConfig
nvidia_config = NvidiaBuilderConfig(
builder_flags={"FP16"},
creation_flags={"STRONGLY_TYPED"}
)
qlip.compile(
model, dynamic_shapes="range",
builder_config=nvidia_config
)