Flux Caching Tutorial: Accelerating Elastic Models with cache-dit¶
This tutorial demonstrates how to apply cache-dit caching techniques to Elastic Flux models for faster inference.
Overview¶
Elastic Models allow you to trade off quality for speed by using different model sizes (S, XL, original). cache-dit is a caching framework that reduces redundant computations during diffusion model inference.
By combining these two approaches, we can achieve significant speedups while maintaining quality.
What we’ll cover:¶
Loading Elastic Flux models in different modes (S, XL, original)
Applying DualCache (aggressive and conservative) caching strategies
Comparing inference times with and without caching
Evaluating image quality metrics
Visualizing results
DualCache Strategies:¶
DualCache Aggressive - High speedup, more caching: - Fn=1, Bn=0
(minimal recomputation) - rdt=0.2 (high threshold for cache
invalidation) - max_continuous_cached_steps=10 (long cache reuse) -
Best for: Static scenes, mid-diffusion steps
DualCache Conservative - Balanced speedup, safer caching: -
Fn=4, Bn=0 (more recomputation layers) - rdt=0.05 (low
threshold, more frequent cache refresh) -
max_continuous_cached_steps=3 (shorter cache reuse) - Best for:
Dynamic scenes, correcting accumulated errors
1. Setup and Imports¶
⚠️ IMPORTANT: Diffusers Version Compatibility
This tutorial uses cache-dit which is designed for newer versions of
diffusers (with Chroma, HiDream models support). However,
elastic_models may require an older version of diffusers.
Two solutions: 1. Use our compatibility patch (recommended) -
see below 2. Manually edit cache-dit - comment out imports in: -
/path/to/cache_dit/cache_factory/patch_functors/functor_chroma.py -
/path/to/cache_dit/cache_factory/patch_functors/functor_hidream.py
Our utils automatically patch missing classes, so cache-dit works with older diffusers.
import os
import sys
import torch
import time
import numpy as np
from pathlib import Path
import matplotlib.pyplot as plt
# Add current directory to path for importing utils
sys.path.insert(0, os.path.dirname(os.path.abspath('__file__')))
from flux_caching_tutorial_utils import (
setup_diffusers_compatibility, set_seed,
visualize_comparison, create_performance_charts,
print_performance_summary, save_results,
)
# Setup compatibility patches BEFORE importing cache-dit
setup_diffusers_compatibility()
# Now import elastic models and cache-dit
from elastic_models.diffusers import (
DiffusionPipeline as ElasticDiffusionPipeline
)
import cache_dit
from cache_dit import (
BasicCacheConfig, BlockAdapter, ForwardPattern
)
# Suppress warnings
import warnings
warnings.filterwarnings('ignore')
print("✓ All imports complete")
2. Configuration¶
# Device and dtype
device = 'cuda' if torch.cuda.is_available() else 'cpu'
dtype = torch.bfloat16
# Model configuration
MODEL_NAME = 'black-forest-labs/FLUX.1-dev'
HF_TOKEN = None # Set your HuggingFace token if needed
HF_CACHE_DIR = '/mount/huggingface_cache'
MODEL_PATH = None
# Generation parameters
WIDTH = 1024
HEIGHT = 1024
NUM_INFERENCE_STEPS = 28
GUIDANCE_SCALE = 3.5
SEED = 42
# Test prompts
TEST_PROMPTS = [
"A majestic lion standing on a rocky cliff at sunset",
"A futuristic city skyline with flying cars and neon lights",
"A beautiful garden with blooming flowers and butterflies",
]
# Output directory
OUTPUT_DIR = Path('./flux_caching_tutorial_results')
OUTPUT_DIR.mkdir(exist_ok=True)
print(f"Device: {device}")
print(f"Model: {MODEL_NAME}")
print(f"Image size: {WIDTH}x{HEIGHT}")
print(f"Inference steps: {NUM_INFERENCE_STEPS}")
print(f"Test prompts: {len(TEST_PROMPTS)}")
Device: cuda
Model: black-forest-labs/FLUX.1-dev
Image size: 1024x1024
Inference steps: 28
Test prompts: 3
3. Core Functions for Elastic Models and Cache-Dit¶
These are the key functions demonstrating how to use cache-dit with elastic_models.
def load_elastic_pipeline(mode='original', model_path=None):
"""
Load Elastic Flux pipeline in specified mode.
This shows how to load elastic models in different configurations:
- 'original': Full model
- 'XL': Larger elastic variant
- 'S': Smaller elastic variant (faster)
"""
print(f"\n{'='*60}")
print(f"Loading Elastic Flux pipeline - Mode: {mode}")
print(f"{'='*60}")
if mode == 'original':
pipeline = ElasticDiffusionPipeline.from_pretrained(
MODEL_NAME,
torch_dtype=dtype,
cache_dir=HF_CACHE_DIR,
token=HF_TOKEN,
device_map=device,
)
else:
# Load elastic model with specific mode
pipeline = ElasticDiffusionPipeline.from_pretrained(
MODEL_NAME,
torch_dtype=dtype,
cache_dir=HF_CACHE_DIR,
token=HF_TOKEN,
mode=mode, # 'XL' or 'S'
device_map=device,
__model_path=model_path,
)
pipeline = pipeline.to(device)
print(f"✓ Pipeline loaded successfully")
return pipeline
def enable_dualcache(pipeline, mode='conservative'):
"""
Enable DualCache on Flux pipeline.
This demonstrates how to apply cache-dit to elastic models:
- 'aggressive': More caching, higher speedup
* Fn=1, rdt=0.2, max_continuous=10
- 'conservative': Safer caching, balanced speedup
* Fn=4, rdt=0.05, max_continuous=3
"""
print(f"\nEnabling DualCache ({mode} mode)...")
# Configure cache parameters based on mode
if mode == 'aggressive':
Fn = 1
Bn = 0
max_warmup_steps = 8
max_continuous_cached_steps = 10
residual_diff_threshold = 0.2
else: # conservative
Fn = 4
Bn = 0
max_warmup_steps = 8
max_continuous_cached_steps = 3
residual_diff_threshold = 0.05
# Create cache configuration
cache_config = BasicCacheConfig(
Fn_compute_blocks=Fn,
Bn_compute_blocks=Bn,
max_warmup_steps=max_warmup_steps,
max_cached_steps=-1,
max_continuous_cached_steps=max_continuous_cached_steps,
residual_diff_threshold=residual_diff_threshold,
)
# Check if blocks are compiled
first_block = pipeline.transformer.transformer_blocks[0]
is_compiled = (
hasattr(first_block, '__wrapped__') or
'Compiled' in type(first_block).__name__
)
# Enable cache using BlockAdapter for Flux architecture
cache_dit.enable_cache(
BlockAdapter(
pipe=pipeline,
transformer=pipeline.transformer,
blocks=[
pipeline.transformer.transformer_blocks,
pipeline.transformer.single_transformer_blocks,
],
forward_pattern=[
ForwardPattern.Pattern_1,
ForwardPattern.Pattern_3,
],
check_forward_pattern=not is_compiled,
),
cache_config=cache_config
)
print(f"✓ DualCache enabled: Fn={Fn}, "
f"rdt={residual_diff_threshold}, "
f"max_continuous={max_continuous_cached_steps}")
def disable_cache(pipeline):
"""Disable cache on pipeline."""
cache_dit.disable_cache(pipeline)
print("✓ Cache disabled")
def generate_and_time(pipeline, prompt, seed=42):
"""Generate image and measure time."""
set_seed(seed)
generator = torch.Generator(device=device).manual_seed(seed)
torch.cuda.synchronize()
start_time = time.time()
result = pipeline(
prompt=prompt,
width=WIDTH,
height=HEIGHT,
num_inference_steps=NUM_INFERENCE_STEPS,
guidance_scale=GUIDANCE_SCALE,
generator=generator,
)
torch.cuda.synchronize()
elapsed = time.time() - start_time
return result.images[0], elapsed
4. Experiment: Mode XL¶
We’ll compare: 1. XL mode without caching (baseline) 2. XL mode with DualCache Aggressive 3. XL mode with DualCache Conservative
results_xl = {}
print("\n" + "="*70)
print("EXPERIMENT: Mode XL")
print("="*70)
# Load XL pipeline
pipeline_xl = load_elastic_pipeline(
mode='XL', model_path=MODEL_PATH
)
✓ Pipeline loaded successfully (Mode: XL)
4.1 XL - No Caching (Baseline)¶
# Warmup
print("\nWarmup...")
_ = generate_and_time(
pipeline_xl, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images without caching
print("\nGenerating images (no caching)...")
images_xl_nocache = []
times_xl_nocache = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_xl, prompt, seed=SEED+i
)
images_xl_nocache.append(image)
times_xl_nocache.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_xl_nocache = np.mean(times_xl_nocache)
print(f"\nAverage time (XL no caching): "
f"{avg_time_xl_nocache:.2f}s")
results_xl['no_cache'] = {
'images': images_xl_nocache,
'times': times_xl_nocache,
'avg_time': avg_time_xl_nocache
}
Average time (XL no caching): 4.17s
4.2 XL - DualCache Aggressive¶
enable_dualcache(pipeline_xl, mode='aggressive')
# Warmup with cache
print("\nWarmup with cache...")
_ = generate_and_time(
pipeline_xl, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images
print("\nGenerating images (DualCache Aggressive)...")
images_xl_aggressive = []
times_xl_aggressive = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_xl, prompt, seed=SEED+i
)
images_xl_aggressive.append(image)
times_xl_aggressive.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_xl_aggressive = np.mean(times_xl_aggressive)
speedup_xl_aggressive = (
avg_time_xl_nocache / avg_time_xl_aggressive
)
print(f"\nAverage time (XL aggressive): "
f"{avg_time_xl_aggressive:.2f}s")
print(f"Speedup: {speedup_xl_aggressive:.2f}x")
cache_stats_xl_aggressive = cache_dit.summary(pipeline_xl)
results_xl['aggressive'] = {
'images': images_xl_aggressive,
'times': times_xl_aggressive,
'avg_time': avg_time_xl_aggressive,
'speedup': speedup_xl_aggressive,
'cache_stats': cache_stats_xl_aggressive
}
disable_cache(pipeline_xl)
✓ DualCache enabled: Fn=1, rdt=0.2, max_continuous=10
Average time (XL aggressive): 2.13s
Speedup: 1.96x
4.3 XL - DualCache Conservative¶
enable_dualcache(pipeline_xl, mode='conservative')
# Warmup with cache
print("\nWarmup with cache...")
_ = generate_and_time(
pipeline_xl, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images
print("\nGenerating images (DualCache Conservative)...")
images_xl_conservative = []
times_xl_conservative = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_xl, prompt, seed=SEED+i
)
images_xl_conservative.append(image)
times_xl_conservative.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_xl_conservative = np.mean(times_xl_conservative)
speedup_xl_conservative = (
avg_time_xl_nocache / avg_time_xl_conservative
)
print(f"\nAverage time (XL conservative): "
f"{avg_time_xl_conservative:.2f}s")
print(f"Speedup: {speedup_xl_conservative:.2f}x")
cache_stats_xl_conservative = cache_dit.summary(pipeline_xl)
results_xl['conservative'] = {
'images': images_xl_conservative,
'times': times_xl_conservative,
'avg_time': avg_time_xl_conservative,
'speedup': speedup_xl_conservative,
'cache_stats': cache_stats_xl_conservative
}
disable_cache(pipeline_xl)
del pipeline_xl
torch.cuda.empty_cache()
✓ DualCache enabled: Fn=4, rdt=0.05, max_continuous=3
Average time (XL conservative): 3.33s
Speedup: 1.25x
5. Experiment: Mode S¶
We’ll compare: 1. S mode without caching (baseline) 2. S mode with DualCache Aggressive 3. S mode with DualCache Conservative
results_s = {}
# Load S pipeline
pipeline_s = load_elastic_pipeline(
mode='S', model_path=MODEL_PATH
)
✓ Pipeline loaded successfully (Mode: S)
5.1 S - No Caching (Baseline)¶
# Warmup
print("\nWarmup...")
_ = generate_and_time(
pipeline_s, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images without caching
print("\nGenerating images (no caching)...")
images_s_nocache = []
times_s_nocache = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_s, prompt, seed=SEED+i
)
images_s_nocache.append(image)
times_s_nocache.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_s_nocache = np.mean(times_s_nocache)
print(f"\nAverage time (S no caching): "
f"{avg_time_s_nocache:.2f}s")
results_s['no_cache'] = {
'images': images_s_nocache,
'times': times_s_nocache,
'avg_time': avg_time_s_nocache
}
Average time (S no caching): 2.71s
5.2 S - DualCache Aggressive¶
enable_dualcache(pipeline_s, mode='aggressive')
# Warmup with cache
print("\nWarmup with cache...")
_ = generate_and_time(
pipeline_s, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images
print("\nGenerating images (DualCache Aggressive)...")
images_s_aggressive = []
times_s_aggressive = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_s, prompt, seed=SEED+i
)
images_s_aggressive.append(image)
times_s_aggressive.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_s_aggressive = np.mean(times_s_aggressive)
speedup_s_aggressive = (
avg_time_s_nocache / avg_time_s_aggressive
)
print(f"\nAverage time (S aggressive): "
f"{avg_time_s_aggressive:.2f}s")
print(f"Speedup: {speedup_s_aggressive:.2f}x")
cache_stats_s_aggressive = cache_dit.summary(pipeline_s)
results_s['aggressive'] = {
'images': images_s_aggressive,
'times': times_s_aggressive,
'avg_time': avg_time_s_aggressive,
'speedup': speedup_s_aggressive,
'cache_stats': cache_stats_s_aggressive
}
disable_cache(pipeline_s)
✓ DualCache enabled: Fn=1, rdt=0.2, max_continuous=10
Average time (S aggressive): 1.45s
Speedup: 1.87x
5.3 S - DualCache Conservative¶
enable_dualcache(pipeline_s, mode='conservative')
# Warmup with cache
print("\nWarmup with cache...")
_ = generate_and_time(
pipeline_s, TEST_PROMPTS[0], seed=SEED
)
print("Warmup complete")
# Generate test images
print("\nGenerating images (DualCache Conservative)...")
images_s_conservative = []
times_s_conservative = []
for i, prompt in enumerate(TEST_PROMPTS):
print(f"\nPrompt {i+1}/{len(TEST_PROMPTS)}: "
f"{prompt}")
image, elapsed = generate_and_time(
pipeline_s, prompt, seed=SEED+i
)
images_s_conservative.append(image)
times_s_conservative.append(elapsed)
print(f"Time: {elapsed:.2f}s")
avg_time_s_conservative = np.mean(times_s_conservative)
speedup_s_conservative = (
avg_time_s_nocache / avg_time_s_conservative
)
print(f"\nAverage time (S conservative): "
f"{avg_time_s_conservative:.2f}s")
print(f"Speedup: {speedup_s_conservative:.2f}x")
cache_stats_s_conservative = cache_dit.summary(pipeline_s)
results_s['conservative'] = {
'images': images_s_conservative,
'times': times_s_conservative,
'avg_time': avg_time_s_conservative,
'speedup': speedup_s_conservative,
'cache_stats': cache_stats_s_conservative
}
disable_cache(pipeline_s)
del pipeline_s
torch.cuda.empty_cache()
✓ DualCache enabled: Fn=4, rdt=0.05, max_continuous=3
Average time (S conservative): 2.59s
Speedup: 1.05x
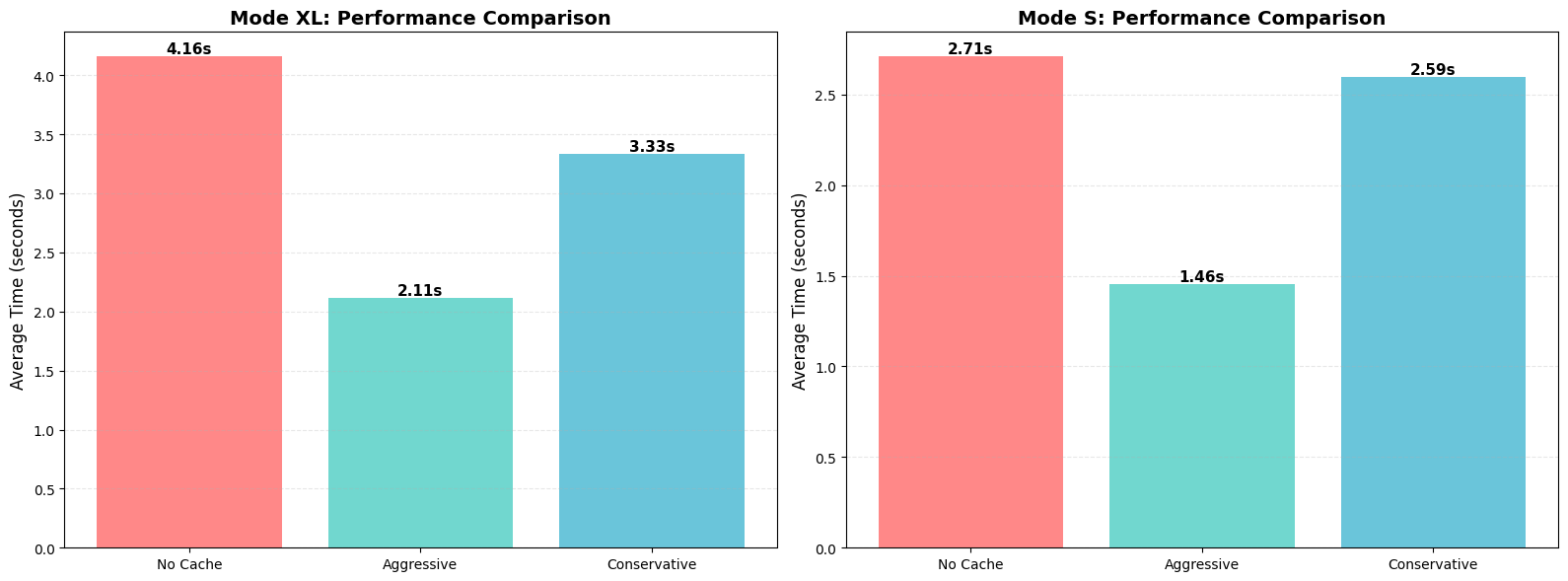
6. Performance Summary¶
# Print performance summary using utility function
print_performance_summary(results_xl, results_s)
================================================================================
PERFORMANCE SUMMARY
================================================================================
--------------------------------------------------------------------------------
MODE XL:
--------------------------------------------------------------------------------
Config Avg Time (s) Speedup Cache Hit Rate
--------------------------------------------------------------------------------
No Cache 4.17 1.00x N/A
Aggressive 2.13 1.96 x 78.9%
Conservative 3.33 1.25 x 35.0%
--------------------------------------------------------------------------------
MODE S:
--------------------------------------------------------------------------------
Config Avg Time (s) Speedup Cache Hit Rate
--------------------------------------------------------------------------------
No Cache 2.71 1.00x N/A
Aggressive 1.45 1.87 x 78.9%
Conservative 2.59 1.05 x 10.0%
--------------------------------------------------------------------------------
OVERALL ANALYSIS:
--------------------------------------------------------------------------------
Fastest configuration: S Aggressive - 1.45s
Best XL speedup from caching: 1.96x
Best S speedup from caching: 1.87x
Recommendations:
• For maximum speed: S + Aggressive Cache
• For quality-critical: XL + Conservative Cache
• For balanced: XL + Aggressive Cache or S + Conservative Cache
================================================================================
7. Visualize Results¶
# Visualize XL results using utility function
print("\nXL Mode Comparison:")
for i in range(len(TEST_PROMPTS)):
visualize_comparison(results_xl, 'XL', TEST_PROMPTS, OUTPUT_DIR, prompt_idx=i)



# Visualize S results using utility function
print("\nS Mode Comparison:")
for i in range(len(TEST_PROMPTS)):
visualize_comparison(results_s, 'S', TEST_PROMPTS, OUTPUT_DIR, prompt_idx=i)



8. Performance Bar Charts¶
# Create performance comparison charts using utility function
create_performance_charts(results_xl, results_s, OUTPUT_DIR)
9. Conclusions¶
Key Findings:¶
Caching provides significant speedups: Both aggressive and conservative caching strategies provide substantial performance improvements over no caching.
Aggressive vs Conservative trade-off:
Aggressive: Higher speedup, but may have slightly lower quality in very dynamic scenes
Conservative: Balanced speedup with better quality preservation
Elastic modes + Caching = Maximum speedup: Combining a smaller elastic model (S) with aggressive caching provides the best performance with acceptable quality trade-offs.
Visual quality: As seen in the comparisons above, the quality difference between caching strategies is often minimal for most prompts.
Recommendations:¶
For production/quality-critical: Use XL + Conservative Cache
For fast iteration/prototyping: Use S + Aggressive Cache
For balanced performance: Use XL + Aggressive Cache or S + Conservative Cache
Next Steps:¶
Try with your own prompts and use cases
Experiment with custom cache configurations (Fn, Bn, rdt parameters)
Measure quality metrics on larger datasets
Combine with other optimizations (quantization, compilation)