Quantization Algorithms¶
Attention
Access to Qlip requires an API token from the TheStage AI Platform and additional access, which can be requested by contacting frameworks@thestage.ai.
QLIP provides advanced quantization algorithms to efficiently compress neural networks while maintaining performance. This section covers three main algorithms: Post-Training Quantization (PTQ), SmoothQuant, Learned Step Size Quantization (LSQ).
Here we will cover the following topics:
Overview¶
The quantization algorithms in QLIP are designed with the following features:
- State-of-the-Art Algorithms
QLIP implements cutting-edge quantization methods for post-training quantization and quantization-aware training.
- Unified Interface Design
All QLIP algorithms follow a consistent API pattern that integrates seamlessly into existing workflows. Whether you’re doing post-training quantization or quantization-aware training, the interface remains intuitive and requires minimal code changes.
- Custimizable quantization schemes
Multiple data types: INT4, INT8, FP8, FP16 with both symmetric and asymmetric quantization
Flexible granularities: Per-tensor, per-channel, per-token quantization for optimal quality-performance trade-offs
Advanced observers: Percentile-based, min-max, and custom observers for accurate scale estimation
Dynamic quantization: Runtime quantization for deployment scenarios requiring maximum flexibility
- Model Architecture Agnostic
QLIP works with any PyTorch model architecture including Transformers (LLaMA, BERT, GPT), Convolutional Neural Networks (ResNet, EfficientNet), and Diffusion Models (Stable Diffusion, DALL-E). The algorithms automatically adapt to different layer types and activation patterns.
API Reference¶
PostTrainingQuantization API¶
- class qlip_algorithms.quantization.PostTrainingQuantization¶
Implementation of post-training quantization that converts pre-trained models to use lower precision without retraining.
PostTrainingQuantization provides static and dynamic quantization with advanced observers for accurate scale/zero-point estimation. It supports flexible granularities (per-tensor, per-channel, per-token) and custom quantization schemes including INT4/8 and FP8.
Static Methods¶
- PostTrainingQuantization.setup_model(model, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-channel', activations_scheme=QuantScheme('int', 8, True), activations_granularity='per-batch', modules_types=(torch.nn.Conv2d, torch.nn.Linear), except_layers=[], placement='input', attention_cls=None, quantization_mode='static', observer=None, observer_kwargs={}, calibration_iterations=np.inf, train_weights_offset=False, train_activations_offset=False, inplace=True, weights_scale_offset_dtype=torch.float32, activations_scale_offset_dtype=torch.float32)¶
Sets up post-training quantization for an entire model by automatically identifying and quantizing specified module types.
Parameters
model: torch.nn.Module - PyTorch model to quantize
weights_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“int”, 8, True) - Quantization scheme for weights (data type, bit-width, symmetric/asymmetric)
weights_granularity: Union[str, QuantGranularity, Dict[str, Any]] = “per-channel” - Quantization granularity for weights (“per-tensor”, “per-channel”, “per-token”)
activations_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“int”, 8, True) - Quantization scheme for activations
activations_granularity: Union[str, QuantGranularity, Dict[str, Any]] = “per-batch” - Quantization granularity for activations
modules_types: tuple = (torch.nn.Conv2d, torch.nn.Linear) - Types of modules to quantize automatically
except_layers: list = [] - List of layer names to exclude from quantization
placement: Union[str, QuantPlacement] = “input” - Determines where quantizers are placed “input” quantizes input activations of modules, “output” quantizes output activations, “attention” sets quantizers for quantized attention kernels
attention_cls: str = None - Name of attention module class for specialized quantization (e.g., ‘MultiheadAttention’)
quantization_mode: str = “static” - Quantization mode (“static” for calibration-based, “dynamic” for runtime)
observer: Observer = None - Observer class for collecting activation statistics (defaults to BoundsObserver)
observer_kwargs: dict = {} - Additional parameters for the observer (e.g., percentile settings)
calibration_iterations: int = np.inf - Maximum number of calibration batches for collecting statistics
train_weights_offset: bool = False - Whether weight zero-points are trainable
train_activations_offset: bool = False - Whether activation zero-points are trainable
inplace: bool = True - Whether to modify the original model or create a copy
weights_scale_offset_dtype: torch.dtype = torch.float32 - Data type for weight quantization parameters
activations_scale_offset_dtype: torch.dtype = torch.float32 - Data type for activation quantization parameters
Returns
Tuple[torch.nn.Module, QuantizationManager, Dict[str, List]]: Tuple containing the quantized model, quantization manager, and parameter groups for optimizers
- PostTrainingQuantization.setup_modules(modules, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-channel', activations_scheme=QuantScheme('int', 8, False), activations_granularity='per-batch', placement='input', quantization_mode='static', observer=None, observer_kwargs={}, calibration_iterations=np.inf, train_weights_offset=False, train_activations_offset=False, weights_scale_offset_dtype=torch.float32, activations_scale_offset_dtype=torch.float32)¶
Sets up post-training quantization for a specific list of modules with fine-grained control.
Parameters
modules: list - List of torch.nn.Module instances to quantize
Other parameters: Same as setup_model method
Returns
QuantizationManager: Quantization manager used to quantize the modules
- PostTrainingQuantization.configure_model(model)¶
Configures model for calibration by setting quantizers to training mode and other modules to evaluation mode.
Parameters
model: torch.nn.Module - Model with quantization already set up
Returns
torch.nn.Module: Configured model ready for calibration
SmoothQuant API¶
- class qlip_algorithms.quantization.SmoothQuant¶
Implementation of SmoothQuant algorithm that addresses activation outliers in transformer models through mathematically equivalent transformations.
SmoothQuant migrates quantization difficulty from activations to weights by applying channel-wise scaling transformations. It identifies outlier channels, applies scaling to reduce activation magnitudes, and compensates in weights to maintain mathematical equivalence. The algorithm enables aggressive quantization of both weights and activations, particularly effective for large language models with severe activation outliers.
Static Methods¶
- SmoothQuant.setup_model(model, transformer_block_type=None, fusion_groups=None, ignore_modules=None, modules_types=(nn.Linear, nn.Conv2d), alpha=0.8, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-tensor', activations_scheme=QuantScheme('int', 8, True), activations_granularity='per-batch', quantization_mode='static', calibration_iterations=128, weights_scale_offset_dtype=torch.float32, activations_scale_offset_dtype=torch.float32, need_sync=False, inplace=True)¶
Sets up SmoothQuant for a transformer model by identifying transformer blocks and applying channel-wise smoothing.
Parameters
model: nn.Module - PyTorch transformer model to apply SmoothQuant
transformer_block_type: Type or str = None - Class type or class name of transformer blocks (e.g., ‘LlamaDecoderLayer’, ‘TransformerBlock’)
fusion_groups: List[Dict[str, Any]] = None - Defines which linear layers should share smoothing scales (defaults to common transformer patterns)
ignore_modules: List[Type] = None - List of module types to exclude from quantization
modules_types: Tuple[Type, …] = (nn.Linear, nn.Conv2d) - Types of modules to quantize
alpha: float = 0.8 - Smoothness migration factor (0.0=no smoothing, 1.0=maximum smoothing). Higher values transfer more difficulty to weights
weights_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“int”, 8, True) - Quantization scheme for weights
weights_granularity: Union[str, QuantGranularity, Dict[str, Any]] = “per-tensor” - Granularity for weight quantization
activations_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“int”, 8, True) - Quantization scheme for activations
activations_granularity: Union[str, QuantGranularity, Dict[str, Any]] = “per-batch” - Granularity for activation quantization
quantization_mode: str = “static” - Quantization mode (“static” or “dynamic”)
calibration_iterations: int = 128 - Number of batches for both equalization and quantization calibration phases
weights_scale_offset_dtype: torch.dtype = torch.float32 - Data type for weight quantization parameters
activations_scale_offset_dtype: torch.dtype = torch.float32 - Data type for activation quantization parameters
need_sync: bool = False - Whether to synchronize statistics across distributed processes
inplace: bool = True - Whether to modify the original model or create a copy
Returns
Tuple[nn.Module, Dict[str, Manager]]: Tuple containing the model with SmoothQuant applied and dictionary of managers
- SmoothQuant.setup_modules(modules, transformer_blocks=None, fusion_groups=None, alpha=0.8, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-channel', activations_scheme=QuantScheme('int', 8, True), activations_granularity='per-batch', quantization_mode='static', calibration_iterations=np.inf, weights_scale_offset_dtype=torch.float32, activations_scale_offset_dtype=torch.float32, need_sync=False)¶
Sets up SmoothQuant for specific transformer blocks and modules with detailed control over fusion groups.
Parameters
modules: List[nn.Module] - List of specific modules to quantize
transformer_blocks: List[nn.Module] = None - List of transformer block instances
fusion_groups: List[Dict[str, Any]] = None - Fusion group configurations defining layer relationships
Other parameters: Same as setup_model method
Returns
Dict[str, Manager]: Dictionary containing quantization and adapter managers
- SmoothQuant.configure_equalization(model)¶
Configures model for the first calibration phase to collect activation statistics for equalization.
Parameters
model: nn.Module - Model with SmoothQuant setup
Returns
nn.Module: Model configured for equalization calibration
- SmoothQuant.configure_quantization(model)¶
Configures model for the second calibration phase to calibrate quantizers with smoothed distributions.
Parameters
model: nn.Module - Model with equalization completed
Returns
nn.Module: Model configured for quantization calibration
- SmoothQuant.fuse_scales(model, transformer_block_type, fusion_groups=None)¶
Fuses smoothing scales into previous normalization layers to reduce computational overhead.
Parameters
model: nn.Module - Model with SmoothQuant applied
transformer_block_type: Type - Transformer block class type
fusion_groups: List[Dict[str, Any]] = None - Fusion group configurations
Learned Step Size Quantization (LSQ) API¶
- class qlip_algorithms.quantization.LSQ¶
Implementation of Learned Step Size Quantization (LSQ) for quantization-aware training.
LSQ learns optimal quantizer step sizes during training by using mathematically principled gradient scaling to balance step size updates with weight updates. The algorithm achieves state-of-the-art accuracy for low-precision neural networks by optimizing network weights and quantization parameters through backpropagation. See LSQ paper for more details.
Static Methods¶
- LSQ.setup_model(model, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-tensor', activations_scheme=QuantScheme('uint', 8, False), modules_types=(torch.nn.Conv2d,), except_layers=[], placement='input', observer=None, observer_kwargs={}, trainable_offsets=False, calibration_iterations=1, inplace=False)¶
Sets up LSQ for an entire model by configuring learnable quantization parameters for specified module types.
Parameters
model: torch.nn.Module - PyTorch model to set up with LSQ
weights_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“int”, 8, True) - Quantization scheme for weights with learnable step sizes
weights_granularity: Union[str, QuantGranularity, Dict[str, Any]] = “per-tensor” - Granularity for weight quantization (“per-tensor” or “per-channel”)
activations_scheme: Union[QuantScheme, Dict[str, Any]] = QuantScheme(“uint”, 8, False) - Quantization scheme for activations with learnable step sizes
modules_types: tuple = (torch.nn.Conv2d,) - Types of modules to apply LSQ quantization
except_layers: list = [] - List of layer names to exclude from LSQ quantization
placement: Union[str, QuantPlacement] = “input” - Determines where quantizers are placed “input” quantizes input activations of modules, “output” quantizes output activations, “attention” sets quantizers for quantized attention kernels
observer: Observer = None - Observer for initial scale/offset estimation (defaults to MinMaxObserver)
observer_kwargs: dict = {} - Additional parameters for the observer
trainable_offsets: bool = False - Whether zero-point offsets are trainable (enables LSQ+)
calibration_iterations: int = 1 - Number of batches for initial quantization parameter estimation
inplace: bool = False - Whether to modify the original model or create a copy
Returns
Tuple[QuantizationManager, torch.nn.Module, Dict[str, List]]: Tuple containing quantization manager, model with LSQ applied, and parameter groups for optimizer configuration
- LSQ.setup_modules(modules, weights_scheme=QuantScheme('int', 8, True), weights_granularity='per-tensor', activations_scheme=QuantScheme('uint', 8, False), placement='input', observer=None, observer_kwargs={}, trainable_offsets=False, calibration_iterations=1)¶
Sets up LSQ for a specific list of modules with fine-grained control over quantization parameters.
Parameters
modules: list - List of torch.nn.Module instances to apply LSQ quantization
Other parameters: Same as setup_model method (excluding model, modules_types, except_layers, inplace)
Returns
QuantizationManager: Manager with LSQ quantization configured for the specified modules
- LSQ.wrap_modules_groups(modules_groups)¶
Applies different LSQ configurations to groups of modules, enabling heterogeneous quantization strategies.
Parameters
modules_groups: list - List of dictionaries, each containing ‘modules’ (list of modules) and ‘config’ (LSQ configuration parameters)
Returns
QuantizationManager: Extended manager with LSQ applied to all module groups with their respective configurations
Note
LSQ Training Requirements: LSQ requires quantization-aware training and cannot be applied post-training. Use higher learning rates (10-100x) for quantization parameters compared to model weights. The algorithm includes built-in gradient scaling to ensure stable training by balancing quantization parameter updates with weight updates.
Post-Training Quantization (PTQ)¶
Post-Training Quantization is the most straightforward quantization method that converts a pre-trained model to use lower precision without requiring retraining.
Basic usage example¶
This simple example shows how to quantize a model to INT8 weights and activations for NVIDIA hardware. The steps are:
Import the
PostTrainingQuantizationalgorithm and NVIDIA static quantization configurationLoad the model
Wrap model with PTQ algorithm
Run calibration data through the model to collect statistics for scale and offset estimation
Run inference on test data to check the quality of the quantized model
from qlip_algorithms.quantization import PostTrainingQuantization
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
import torch
model = torch.load('model.pth')
# Setup PTQ with INT8 weights and activations
model, handle = PostTrainingQuantization.setup_model(
model=model,
**NVIDIA_INT_W8A8,
calibration_iterations=256
)
# Run calibration data through the model
with torch.no_grad():
for i, batch in enumerate(calibration_dataloader):
model(batch)
if i > 256: # run only 256 batches for calibration
break
Setting custom modules for quantization¶
By default PostTrainingQuantization.setup_model will use all linear and convolutional layers in the model for quantization.
Below we use PostTrainingQuantization.setup_modules method to quantize only linear layers except layers with fc in the name.
modules = [
module for name, module in model.named_modules()
if isinstance(module, torch.nn.Linear) and 'fc' not in name
]
model, handle = PostTrainingQuantization.setup_modules(
modules=modules, **NVIDIA_INT_W8A8, calibration_iterations=256
)
Quantization schemes¶
Quantize model to align with NVIDIA hardware. Static int8 weights and activations quantization scheme:
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
model, handle = PostTrainingQuantization.setup_model(
model=model, **NVIDIA_INT_W8A8, calibration_iterations=256
)
For higher accuracy of quantized model use dynamic quantization scheme:
from qlip.compiler.nvidia import NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
model, handle = PostTrainingQuantization.setup_model(
model=model, **NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
)
Note
When using dynamic quantization no need to calibrate model on calibration data. Scales are calculated on the fly during inference.
Quantize model attention layers to use NVIDIA FP8 attention kernels:
from qlip.compiler.nvidia import NVIDIA_FLOAT_W8A8
# extract attention modules from model
modules = [module for module in model.modules() if isinstance(module, Attention)]
# setup PTQ with FP8 quantization scheme with placement='attention'
handle = PostTrainingQuantization.setup_modules(
modules=modules, **NVIDIA_FLOAT_W8A8,
calibration_iterations=256, placement='attention'
)
Custom weights and activations quantization schemes¶
We already saw how to use quantization schemes configured for compatibility with NVIDIA hardware. Below we show how to set up custom quantization schemes to quantize model to 4-bit weights and 8-bit activations.
PostTrainingQuantization.setup_model(
model=model,
weights_scheme={'scheme': 'int', 'bits': 4, 'symmetric': True},
activations_scheme={'scheme': 'uint', 'bits': 8, 'symmetric': False},
calibration_iterations=256
)
Quantization scale and zero-point estimation¶
Activations quantizers use observers mechanism to collect statistics for quantization scale and offset estimation.
By default PercentileObserver is used. It calculates percentile_min and percentile_max of observed distribution to obtain left and right boundaries of the quantized interval.
Here is example how to specify percentile values for left and right boundaries:
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
model, handle = PostTrainingQuantization.setup_model(
model=model, **NVIDIA_INT_W8A8,
observer_kwargs={'percentile_min': 0.05, 'percentile_max': 0.95}
)
Implement custom observer to use absoulte minimum and maximum values of activations to build boundaries of the distribution.
from qlip.base.observers import BaseObserver
class CustomObserver(BaseObserver):
def _update(self, activations: torch.Tensor) -> None:
""" Collects minimal and maximal values of activations. """
if hasattr(self, '_min'):
self._min = min(torch.min(activations), self._min)
else:
self._min = torch.min(activations)
if hasattr(self, '_max'):
self._max = max(torch.max(activations), self._max)
else:
self._max = torch.max(activations)
def get_stats(self) -> Tuple[torch.Tensor, torch.Tensor]:
""" Method should return estimated left and right boundaries of the distribution. """
return self._min, self._max
model, handle = PostTrainingQuantization.setup_model(
model=model, **NVIDIA_INT_W8A8, observer=CustomObserver
)
Running with distributed data parallel¶
To run with distributed data parallel, use need_sync=True parameter in observer kwargs.
It will synchronize statistics of quantized modules across all processes, thus after calibration each process will have the same quantization parameters.
model, handle = PostTrainingQuantization.setup_model(
model=model, **NVIDIA_INT_W8A8,
observer_kwargs={'need_sync': True}
)
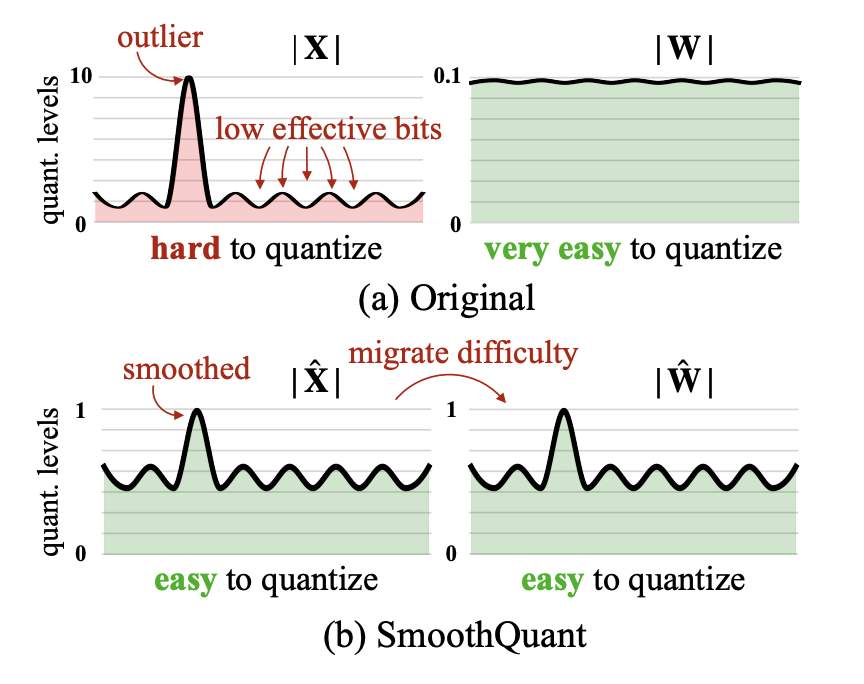
SmoothQuant¶
SmoothQuant addresses the challenge of quantizing models with activation outliers by migrating the quantization difficulty from activations to weights through mathematically equivalent transformations. It applies channel-wise equalization to balance the quantization difficulty. See SmoothQuant paper for more details.
Basic usage example¶
Wrap model with SmoothQuant algorithm¶
Below we wrap model with INT8 weights and activations quantization scheme for NVIDIA hardware using SmoothQuant algorithm.
from qlip_algorithms.quantization import SmoothQuant
from qlip.compiler.nvidia import NVIDIA_INT_W8A8
from transformers import AutoModelForCausalLM
# Load transformer model
model = AutoModelForCausalLM.from_pretrained('meta-llama/Meta-Llama-3.1-8B')
# Setup SmoothQuant
model, handle = SmoothQuant.setup_model(
model=model,
calibration_iterations=512,
**NVIDIA_INT_W8A8
)
Calibration of SmoothQuant algorithm¶
Calibration of SmoothQuant algorithm is done in two steps:
Step 1**: First half of calibration_iterations will be used to collect activation statistics to identify outlier channels that are difficult to quantize.
Step 2**: Next half of calibration_iterations will be used to apply channel-wise smoothing and calibrate quantization parameters (scales and zero-points).
for batch in calibration_dataloader:
model(**batch)
Quantization schemes¶
To obtain higher accuracy of quantized model use per-token dynamic quantization scheme:
from qlip.compiler.nvidia import NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
model, handle = SmoothQuant.setup_model(
model=model, **NVIDIA_INT_W8A8_PER_TOKEN_DYNAMIC
)
Note
SmoothQuant supports all the same quantization schemes as PTQ.
Smoothing factor (α)¶
To balance the quantization difficulty SmoothQuant applies the following transformation: Y = (diag(s)^(-1) * X) * (diag(s) * W)
where s is the scaling factor controlled by parameter α.
It controls the migration strength between activations and weights.
α = 0: quantization difficulty migration from weights to activationsα = 0.5: Balanced migrationα = 0.8: Optimal in most casesα = 1.0: Full migration from activations to weights
Typically, for larger models, larger α values tend to yield better results. For LLama-3.1-8B, α = 0.8 is a good choice.
Fusion of equalization operations¶
SmoothQuant performs equalization of activations before it’s quantized.
These operations may be fused to previous layers such as LayerNorm or RMSNorm to avoid redundant computations while preserving mathematical equivalence.
Let’s suppose we are working with LLama-3.1-8B model. In LlamaDecoderLayer before query, key, value projections there is a LayerNorm module, so
we can fuse equalization operations of these projections to the layernorm module, but to do that we need to have the same equalization factor for all 3 projections.
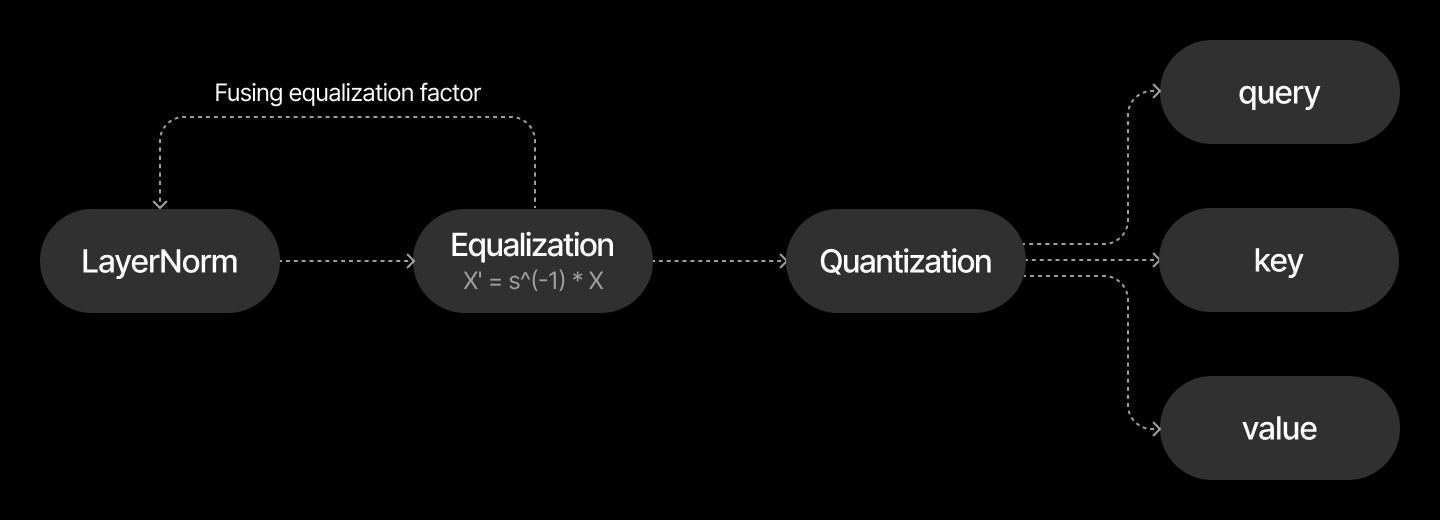
Below is an example of how to configure the algorithm to share equalization factor for specific modules.
For this we need to specify transformer block type and pass fusion_groups dict
with keys - name of the module to fuse to, values - list of linear modules whose equalization factor will be fused to the key.
from qlip_algorithms.quantization import SmoothQuant
fusion_groups = {
'input_layernorm': ['self_attn.q_proj', 'self_attn.k_proj', 'self_attn.v_proj']
}
model, handle = SmoothQuant.setup_model(
model=model,
fusion_groups=fusion_groups,
transformer_block_type='LlamaDecoderLayer',
**NVIDIA_INT_W8A8,
)
# ... Calibrate
Once model is calibrated, use SmoothQuant.fuse_scales to fuse equalization operations to the specified modules.
SmoothQuant.fuse_scales(model, transformer_block_type='LlamaDecoderLayer', fusion_groups=fusion_groups)
Save checkpoint with QlipConfig:
from qlip import QlipConfig
config = QlipConfig.from_model(model)
config.save('config.pth')
Note
In theory it’s better to make such offline fusion of equalization operations if it’s possible to avoid overheads related to on fly equalization operations, but in practice compiler usually fuses these operations itself, so the overhead is negligible.
Learned Step Size Quantization (LSQ)¶
Learned Step Size Quantization (LSQ) is a quantization-aware training method that learns optimal quantizer step sizes during training, achieving state-of-the-art accuracy for low-precision neural networks. Unlike post-training quantization methods, LSQ optimizes both network weights and quantization parameters. See LSQ paper for more details.
Note
LSQ requires quantization-aware training and cannot be applied post-training like PTQ. The method learns quantization parameters with model weights, requiring access to training data.
When to Use LSQ:
When highest accuracy is required for low-bit quantization
When training data and computational resources are available
For models where post-training quantization shows significant accuracy degradation
Basic usage example¶
Here is an example of how to use LSQ to quantize a model to 4-bit weights and 8-bit activations. The algorithm workflow is:
Setup LSQ with 4-bit weights and 8-bit activations
Run calibration on representative data to estimate initial quantization parameters
Setup optimizer
Train the model as usual
from qlip_algorithms.quantization import LSQ
import torch
import torch.optim as optim
# Setup LSQ with 4-bit weights and 8-bit activations
handle, quantized_model, param_groups = LSQ.setup_model(
model=model,
weights_scheme={'scheme': 'int', 'bits': 4, 'symmetric': True},
activations_scheme={'scheme': 'uint', 'bits': 8, 'symmetric': False},
calibration_iterations=32
)
# Run calibration on representative data to estimate initial quantization parameters
for batch in calibration_dataloader:
quantized_model(batch)
# Setup optimizer with quantization parameter groups
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Training loop with LSQ
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer.zero_grad()
output = quantized_model(batch['input'])
loss = criterion(output, batch['target'])
loss.backward()
optimizer.step()
Setting different learning rate for quantization parameters¶
handle, quantized_model, param_groups = LSQ.setup_model(
model=model,
weights_scheme={'scheme': 'int', 'bits': 4, 'symmetric': True},
activations_scheme={'scheme': 'uint', 'bits': 8, 'symmetric': False},
calibration_iterations=32
)
optimizer = optim.SGD([
{'params': param_groups['model'], 'lr': 1e-4},
# Higher LR for quantization scales parameters
{'params': param_groups['scales'], 'lr': 1e-2}
])
Serialize and deserialize quantized model¶
Save quantized model checkpoint to file:
from qlip import QlipConfig
config = QlipConfig.from_model(quantized_model)
config.save('config.pth')
Apply quantization configuration to model from file:
from qlip import QlipConfig
config = QlipConfig.from_file('config.pth')
model = config.apply(model)